Строчные или колончатые таблицы?
Всем, привет, я нахожусь в поиске работы на позицию Junior Data Engineer. И сейчас читаю различного рода статьи, которые должны помочь при прохождении собеседований. В этом посте я хочу поделиться одной из тем, которая часто обсуждается на технических собеседованиях — выбор между колоночным и строковым хранением данных в СУБД. Это знание важно для проектирования эффективных решений и оптимизации работы с данными. Статья на которой основан пост: https://bigdataschool.ru/blog/columnar-and-row-based-databases.html
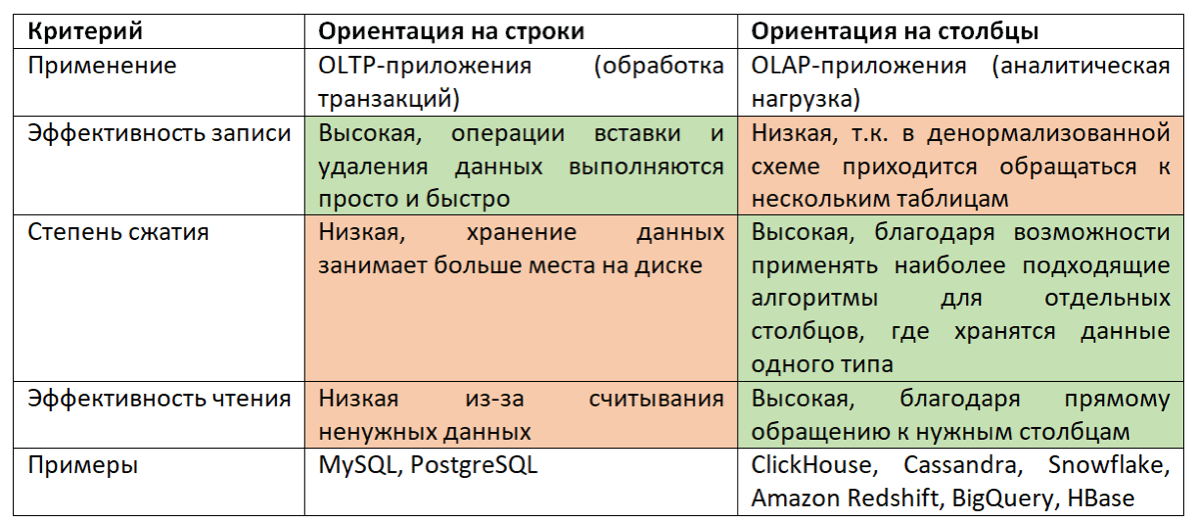
Строковые и колоночные базы данных: в чем разница? Когда мы говорим о строковых базах данных, мы подразумеваем, что данные хранятся по строкам. Каждый блок данных на диске содержит информацию обо всех атрибутах конкретной строки. Такой подход особенно хорош для транзакционных систем (OLTP), где важно быстро и целиком обработать одну или несколько записей — например, при внесении новой строки или обновлении существующей. PostgreSQL и MySQL являются классическими примерами баз данных, ориентированных на строки. Они удобны для приложений, которым нужно часто взаимодействовать с большинством полей таблицы одновременно.
Но что если запросы в основном затрагивают лишь несколько столбцов, а не всю строку? Здесь на помощь приходят колоночные базы данных. Они хранят данные не по строкам, а по столбцам, что позволяет быстро считывать и обрабатывать только те поля, которые нужны для конкретного аналитического запроса. Это делает колоночные базы данных отличным выбором для аналитических систем (OLAP), где часто выполняются сложные запросы по большим объемам данных, но с использованием небольшого количества атрибутов. Например, такие базы данных, как ClickHouse, Amazon Redshift и Google BigQuery, оптимизированы для работы с Big Data, обеспечивая высокую скорость обработки и сжатие данных за счет однотипных значений в столбцах.
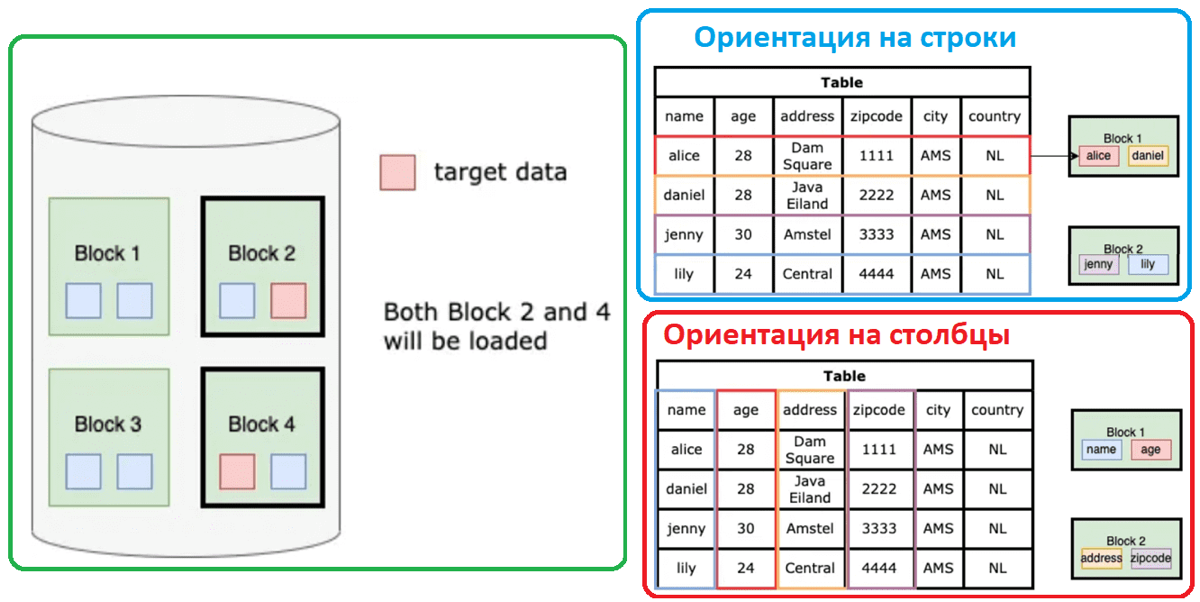
Как это влияет на производительность? В строковых базах данных все атрибуты строки хранятся вместе, поэтому при чтении строки с диска сразу загружаются все ее поля, даже если они не нужны. Это приводит к избыточному чтению данных, что может замедлить выполнение запросов, когда требуется только часть информации.
В колоночных же базах данных данные организованы так, что можно считывать только нужные столбцы. Это сильно снижает объем данных, который нужно загрузить в память, и ускоряет выполнение аналитических запросов. К тому же, колоночные базы данных могут использовать более эффективные алгоритмы сжатия, так как все данные в одном столбце обычно однотипные.
Например, если вам нужно вычислить средний возраст клиентов из миллиона записей, в колоночной базе данных будет загружен только столбец с возрастом, в то время как в строковой базе будет загружена каждая строка целиком.
Гибридные базы данных Современные базы данных, такие как Greenplum и Teradata, поддерживают как строковую, так и колоночную ориентацию хранения данных. Это позволяет использовать их как для транзакционных, так и для аналитических нагрузок, гибко настраивая архитектуру под конкретные задачи. В таких системах можно выбрать, как хранить каждую отдельную таблицу: по строкам для частого добавления и изменения данных или по столбцам для быстрой аналитики.
Заключение Понимание различий между строковым и колоночным хранением данных — это не только важная часть работы любого дата-инженера, но и часто обсуждаемая тема на собеседованиях. Выбор архитектуры базы данных напрямую влияет на производительность и масштабируемость системы, и знание того, когда использовать тот или иной подход, поможет вам разрабатывать более эффективные решения.
Оставайтесь на связи — впереди еще больше полезной информации для тех, кто готовится к собеседованиям и хочет углубиться в инженерные аспекты работы с данными!