
Ilya Gasan
Data engineer Газпром нефть · 29.10
Мой поиск работы занял около 3 месяцев, в течение которых я активно погружался в мир Data Engineering. За это время я изучил основы проектирования хранилищ данных, познакомился с инструментами для создания ETL и ELT процессов, а также изучил различные архитектуры построения дата-центров. Это был интенсивный период, за который я не только приобрел новые навыки, но и создал несколько проектов, применив полученные знания на практике.
На чем я концентрировался в процессе обучения:
Я сосредоточился на изучении следующих инструментов и технологий, чтобы уверенно работать с большими данными и управлять данными в реальном времени:
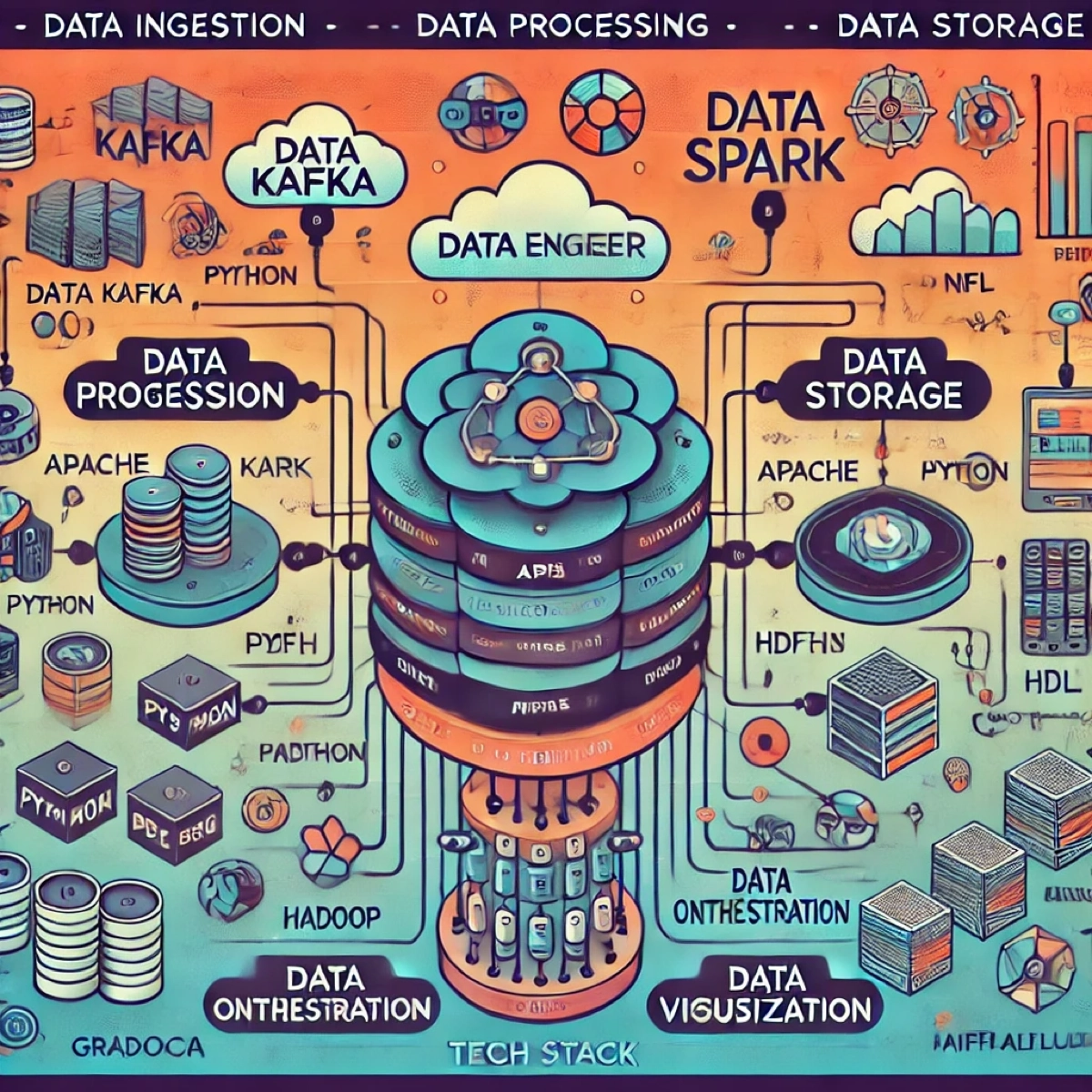
• Python — основа для написания ETL/ELT процессов и обработки данных. • Apache Airflow — для оркестрации и автоматизации рабочих процессов. • Docker — контейнеризация приложений для повышения гибкости и совместимости. • Apache Kafka — передача данных в реальном времени. • PostgreSQL — реляционная база данных для хранения структурированных данных. • Greenplum — аналитическая база данных, оптимизированная для больших объемов данных. • Hadoop — система для распределенного хранения и обработки данных. • Apache Spark — для распределенной обработки данных, что позволяет работать с большими объемами быстрее и эффективнее.
Мои проекты на GitHub:
В процессе обучения я разработал несколько проектов, которые можно найти на моем GitHub. Они продемонстрировали мою способность интегрировать различные инструменты и технологии для решения задач по обработке данных:
• NASA API to Kafka to MySQL: Проект, в котором данные с NASA API передаются в Kafka, а затем сохраняются в базе данных MySQL. Здесь я использовал Kafka для потоковой передачи данных и продемонстрировал, как можно интегрировать API, Kafka и базу данных в единую цепочку. • Пайплайн для данных из JSONPlaceholder API: Этот проект представляет собой ETL-процесс, который загружает данные с JSONPlaceholder API и обрабатывает их для дальнейшего анализа. Использовал Airflow для автоматизации загрузки данных и их сохранения в структуру, пригодную для анализа. • Weather Data Multithreading with PostgreSQL: Пример многопоточной обработки данных о погоде, которые затем сохраняются в PostgreSQL. Проект показывает, как можно параллельно обрабатывать данные и сохранять их в базу данных, что особенно важно при работе с большими объемами информации в реальном времени. • Импорт данных из PostgreSQL в HDFS с помощью Sqoop и Airflow: В этом проекте я использовал Sqoop для переноса данных из PostgreSQL в HDFS, управляя процессом с помощью Airflow. Это позволило реализовать простой, но эффективный ETL-процесс для работы с большими данными в распределенной системе хранения. • Installation Guide for Grafana, Prometheus, and Node Exporter: Руководство по установке и настройке Grafana, Prometheus и Node Exporter. Этот проект показывает, как настроить мониторинг и визуализацию данных, что полезно для анализа производительности и контроля системы. • Yolo Detection with On-Device Decoding: Проект, основанный на использовании Yolo для детектирования объектов. Я настроил on-device decoding, чтобы повысить скорость обработки и сократить объем данных, передаваемых на сервер для дальнейшего анализа.
Итог: вы можете посмотреть мой гит просмотреть проекты, изучить код и дополнить Вашу базу знаний, также советую освоить большую часть стека и инструментов, для разработки!
Следующий пост будет касаться использования airflow в направлении инженеринга данных
напишите коммент

Stepan Lapin
· 29.10
🔥🔥🔥
ответить
еще контент автора
еще контент автора
Ilya Gasan
Data engineer Газпром нефть · 29.10
войдите, чтобы увидеть
и подписаться на интересных профи
в приложении больше возможностей
пока в веб-версии есть не всё — мы вовсю работаем над ней
cоциальная сеть для нетворкинга от hh.ru
пересекайтесь с теми, кто повлияет на ваш профессиональный путь
сетка — cоциальная сеть для нетворкинга от hh.ru
пересекайтесь с теми, кто повлияет на ваш профессиональный путь