

Makrushin
Денис Макрушин, Chief Product Officer, Yandex · 22.11
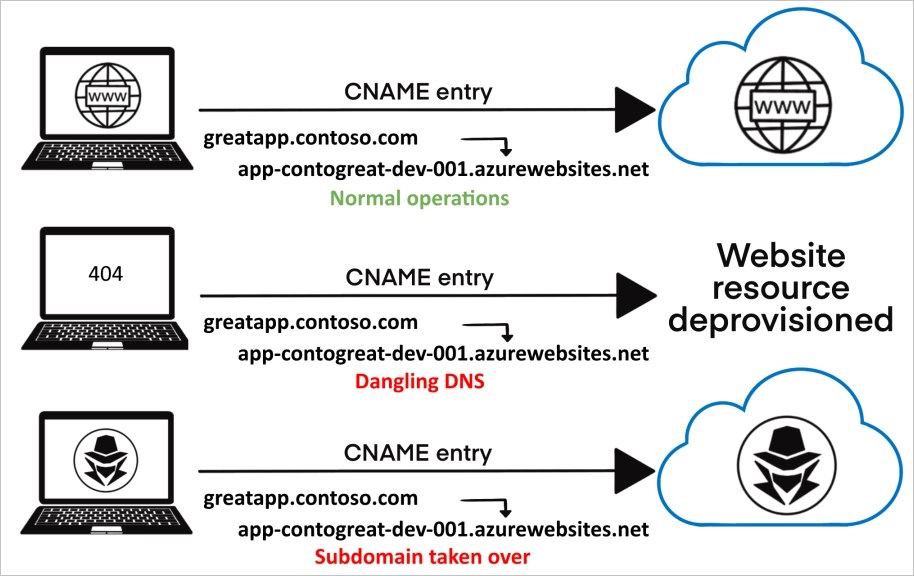
Поиск секретов и уязвимостей dangling DNS в больших данных
Когда мы используем традиционные методы поиска уязвимостей, то ограничиваемся исследованием конкретной цели: платформы, приложения, веб-ресурса, сегмента сети. Но есть подход, который отличается от классического: не ограничиваться конкретной целью, а выбрать определенную уязвимость и заняться ее поиском в больших данных.
С переходом инфраструктуры в облака, второй метод может дать интересные результаты. Например, если на большом пуле IP-адресов крупных облачных провайдеров вроде Google и AWS поискать “висячие” DNS-записи (dangling DNS), которые указывают на несуществующий ресурс и доступны для захвата (например, для атак subdomain takeover), то можно обнаружить много возможностей для атак subdomain takeover.
Более 78000 “висячих” DNS-записей, которые указывают на 66000 уникальных доменов верхнего уровня. Среди владельцев этих доменов есть крупные компании и бренды, а значит, злоумышленник может разместить на этих доменах свой ресурс, который будет эксплуатировать доверие пользователей.
Аналогичный подход можно применить и к поиску секретов в файлах. Если взять источник вроде Virustotal и с помощью YARA-правил поискать в нем файлы с секретами, то можно обнаружить более 15000 секретов. Среди них: 2500 ключей для подключения к инфраструктуре OpenAI, 3000 ключиков для AWS и Google Cloud.
Подход поиска уязвимостей в больших данных состоит из ключевых принципов:
- начинать исследование с уявзимости и ее особенностей, а не с цели;
- использовать все доступные источники данных, включая нетривиальные источники;
- данные, по которым ведется поиск, должны иметь связь с заданным классом уязвимостей;
- процесс поиска по большим данным должен быть масштабируемым.
Применяй этот подход, чтобы освежить свои исследования.
напишите коммент
еще контент автора
еще контент автора
Makrushin
Денис Макрушин, Chief Product Officer, Yandex · 22.11
войдите, чтобы увидеть
и подписаться на интересных профи
в приложении больше возможностей
пока в веб-версии есть не всё — мы вовсю работаем над ней
cоциальная сеть для нетворкинга от hh.ru
пересекайтесь с теми, кто повлияет на ваш профессиональный путь
сетка — cоциальная сеть для нетворкинга от hh.ru
пересекайтесь с теми, кто повлияет на ваш профессиональный путь