

Java Development
Александр Вотин, Backend developer · 10.12 · ред.
Обрабатка Unicode в Java. Это важно знать
Представь, что ты путешествуешь по всему миру и решаешь познакомиться с культурами разных стран. Но вот беда — все говорят на разных языках. Как ты будешь понимать всех, если в твоем багаже есть только один универсальный словарь? Ответ прост, ты возьмешь с собой всемирно признанный мультиязычный словарь — Unicode. И Java, как и ты, пользуется этим универсальным инструментом, чтобы обработать все возможные символы из разных уголков Земли. Unicode — это стандарт, который задает универсальный набор символов для всех языков мира. Он был создан, чтобы избежать проблем с различными кодировками, которые вели к непониманию между системами и программами. В Unicode есть не только буквы и цифры, но и символы разных письменностей, эмодзи, математические знаки и даже древние руны. Как Java использует Unicode? Java с самого начала была задумана как кросс-платформенный язык. Это означало, что программы, написанные на Java, должны одинаково работать на разных устройствах и в разных странах. И вот тут на сцену выходит Unicode. Java использует Unicode в своей внутренней репрезентации строк. В отличие от старых языков, которые использовали локальные кодировки (например, ASCII или Windows-1251 для русского), Java хранит строки в формате Unicode, что позволяет без проблем работать с текстами на любом языке. В Java символы хранятся в типе данных char. Вот тут и начинается интересное. Тип char в Java представляет собой 16-битное число, что означает, что Java использует 16 бит для кодировки одного символа. Благодаря этому, Java может использовать символы из стандартной таблицы Unicode, которая вмещает 65536 различных символов. То есть любой символ, будь то латинская буква, китайский иероглиф или даже эмодзи, может быть представлен в Java. Но что делать, если символов больше, чем 65536? Для этого существуют составные символы, которые Java поддерживает через механизм surrogate pairs (замещающие пары). Эти пары позволяют представлять символы, которые выходят за пределы 16-битного диапазона, с помощью двух char переменных. Вот пример на изображении, который покажет, как можно работать с Unicode-символами в Java. - Мы используем символы с помощью их Unicode-значений, записанных через \u (например, \u2764 — это сердце ❤️). - Когда мы пишем "👨💻", Java использует два символа (для мужчины и ноутбука), но отображает их как один — это пример использования суррогатных пар. Каждый символ в Java занимает 2 байта (16 бит). Это может быть неэффективно для некоторых языков, использующих гораздо меньше символов, чем в Unicode. Однако для большинства задач это не является проблемой. Не все символы умещаются в 16 бит. Эмодзи, например, занимают два символа. Это важно учитывать при манипуляциях с текстами. - Важно помнить, что Java работает с Unicode внутри программы, но при чтении и записи данных (например, с файлами или базами данных) может понадобиться указание нужной кодировки (UTF-8, UTF-16 и т.д.). Java справляется с Unicode как профессиональный полиглот, легко переваривая любые символы и строки. Но помни, что важно учитывать такие моменты, как суррогатные пары и кодировки при взаимодействии с внешними источниками данных.
#АлександрВотин #JavaDevelopment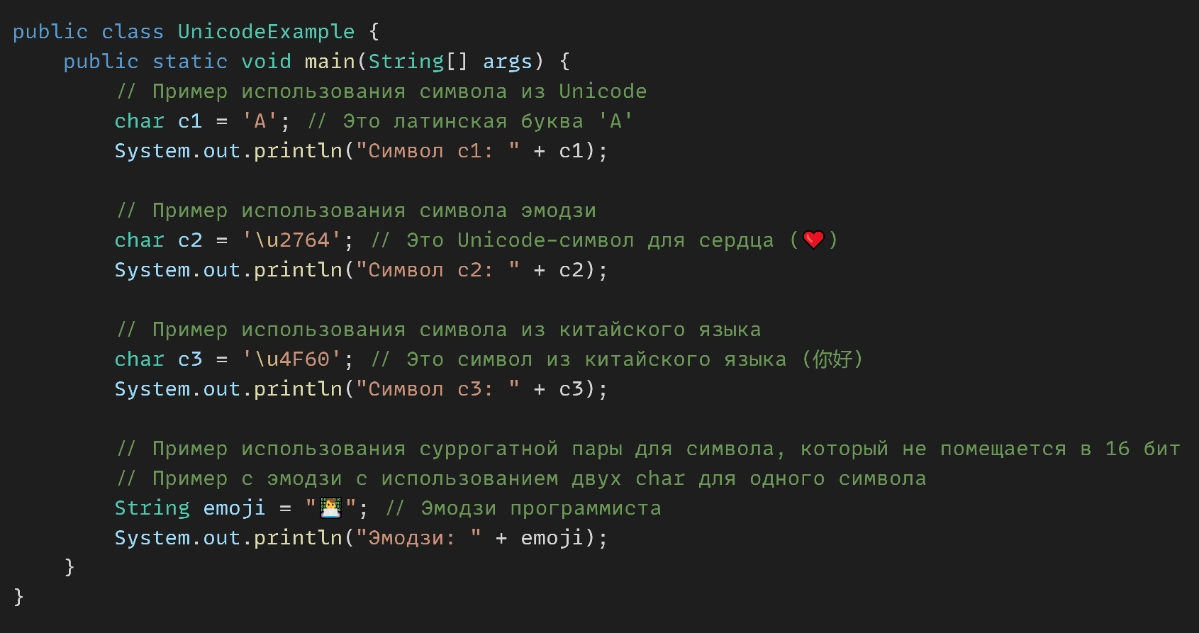
напишите коммент
еще контент автора
еще контент автора
Java Development
Александр Вотин, Backend developer · 10.12 · ред.
войдите, чтобы увидеть
и подписаться на интересных профи
в приложении больше возможностей
пока в веб-версии есть не всё — мы вовсю работаем над ней
cоциальная сеть для нетворкинга от hh.ru
пересекайтесь с теми, кто повлияет на ваш профессиональный путь
сетка — cоциальная сеть для нетворкинга от hh.ru
пересекайтесь с теми, кто повлияет на ваш профессиональный путь