
Аналитика на вырост
28.03
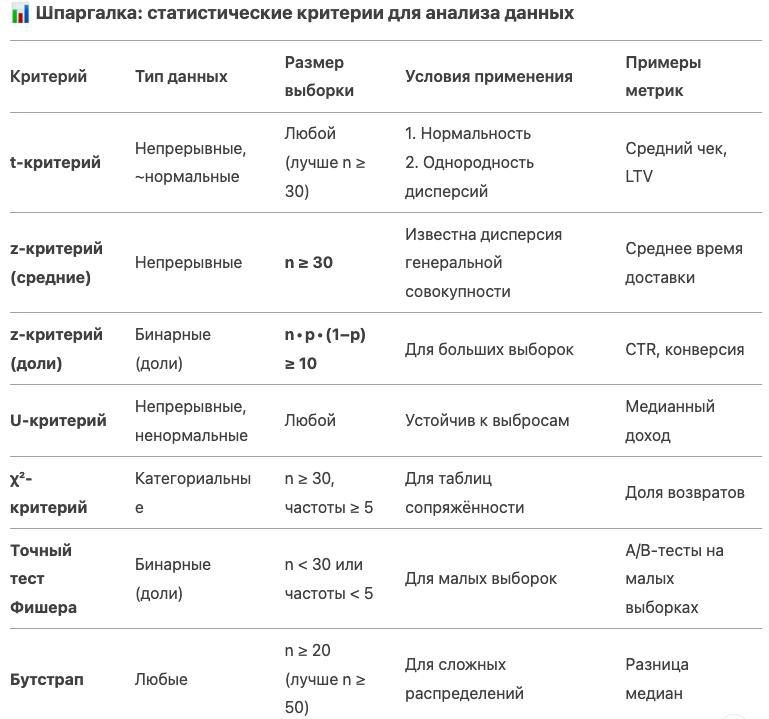
📊 Cтатистические критерии: от t-теста до Фишера 👋 Всем привет! Недавно вспоминала статистику и решила написать пост-шпаргалку, чтобы структурировать информацию и освежить память. Решила и вам будет полезно, все-таки на математических секциях нередко спрашивают про такое)
🔍 1. Критерии для сравнения средних
1️⃣ t-критерий Стьюдента
📌 Для чего: Сравнение средних значений (средний чек, время до покупки). 📌 Условия: - Распределение близко к нормальному / нормальное - Дисперсии в группах примерно равны (тест Левена) 📌 Особенности:: - Для малых выборок (n<30) — t-тест (если данные нормальные). - Для больших выборок (n≥30) — t-тест или z-тест (разница незначительна). 📌 Когда использовать: Изменяем цену → смотрим на средний чек
2️⃣ z-критерий 📌 Для чего: Аналог t-теста для больших выборок (n > 30) 📌 Особенности: Есть z-критерий для долей (пропорций) — это отдельный тест, основанный на нормальном приближении биномиального распределения, используется для сравнения конверсий.
📉 2. Критерии для ненормальных данных 3️⃣ U-критерий Манна-Уитни 📌 Для чего: Сравнение распределений для ненормальных данных (доходы, время в приложении). 📌 Особенности: - Работает с порядковыми данными - Устойчив к выбросам 📌 Когда использовать: - Тестируем новую монетизацию → сравниваем медианный доход
📊 3. Критерии для долей и частот 4️⃣ χ²-критерий (хи-квадрат) 📌 Для чего: Сравнение долей (CTR, конверсия). 📌 Условия: - Ожидаемые частоты > 5 - Размер выборки > 30 📌 Поправки: - Йейтса — для таблиц 2×2
5️⃣ критерий Фишера (точный тест Фишера) 📌 Для чего: Сравнение долей в малых выборках (n < 30) 📌 Условия: - Малые выборки (n<30). - Ожидаемые частоты в ячейках таблицы < 5 (нарушение условия χ²). - Несбалансированные группы (например, 3 vs 20 наблюдений). 📌 Особенности: - Даёт точное p-value - Вычислительно сложен для больших таблиц 📌 Пример: Тестируем изменение на 20 пользователях → используем Фишера.
🔄 4. Непараметрические и сложные случаи 6️⃣ Бутстрап 📌 Для чего: Когда данные сложные или распределение неизвестно. 📌 Как работает: 1. Многократно рандомно перевыбираем подвыборки с возвращением (т.е. один элемент может попасть в выборку несколько раз) 2. Строим распределение статистики 3. Считаем доверительный интервал и оцениваем стандартную ошибку 📌 Плюсы: - Работает почти для любых данных, где n > 10 (но рекомендуют брать выборки побольше, конечно) - Можно оценить разницу медиан, квантилей
🚨 Главные ошибки
❌ Использовать χ² для малых выборок → ложные результаты! ❌ Применять t-тест к ненормальным данным → U-тест надежнее ❌ Игнорировать поправки → завышенная значимость
💡 Практические советы
✅ Всегда проверяйте распределение (QQ-plot, тест Шапиро-Уилка) ✅ Следите за мощностью теста — рассчитывайте размер выборки и длительность эксперимента заранее
Ставьте: 🔥- если вам нравятся посты про статистику 👀 - если ждете более продуктовый пост
напишите коммент
еще контент в этом сообществе
еще контент в этом соообществе
Аналитика на вырост
28.03
войдите, чтобы увидеть
и подписаться на интересных профи
в приложении больше возможностей
пока в веб-версии есть не всё — мы вовсю работаем над ней
cоциальная сеть для нетворкинга от hh.ru
пересекайтесь с теми, кто повлияет на ваш профессиональный путь
сетка — cоциальная сеть для нетворкинга от hh.ru
пересекайтесь с теми, кто повлияет на ваш профессиональный путь