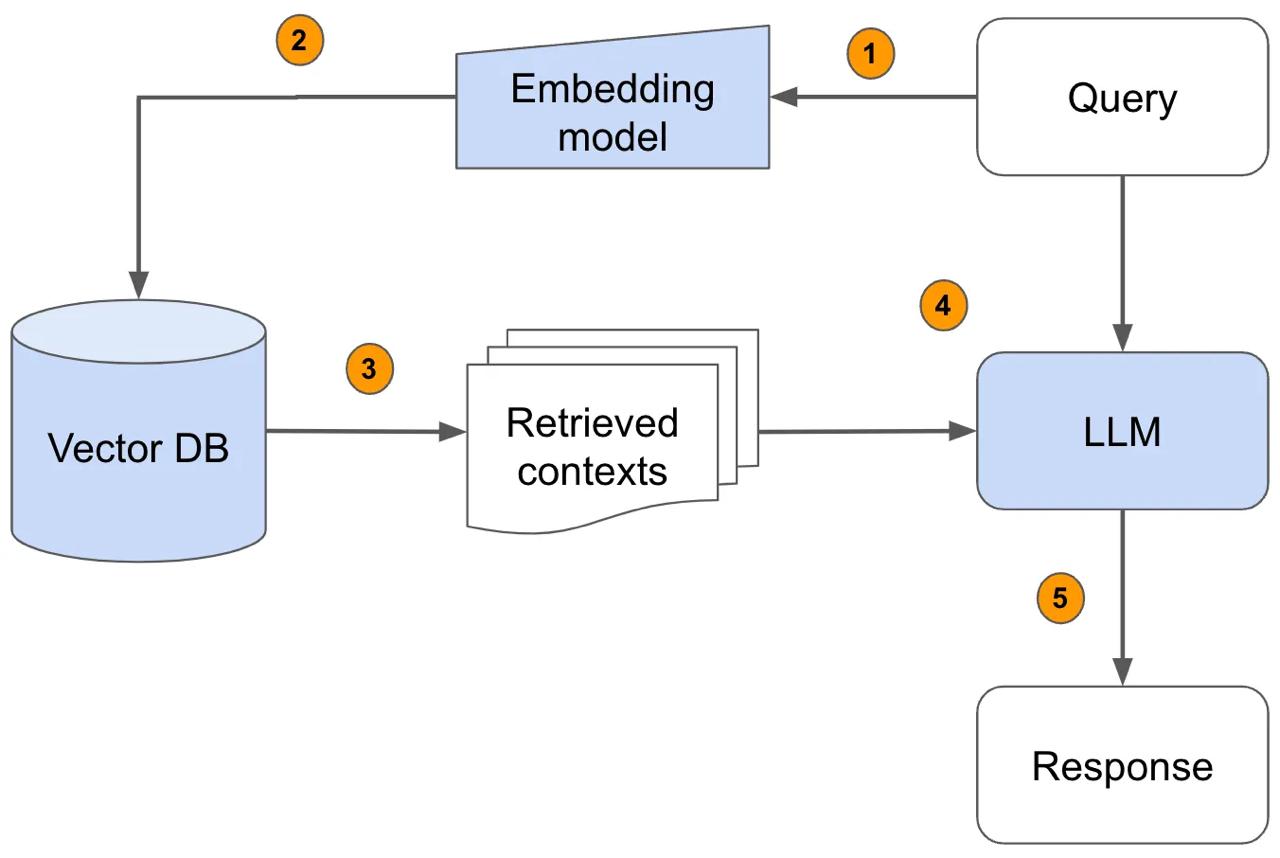
Что такое Retriever и зачем он нужен?На схеме изображен классический вариант RAG (Retrieval Augmented Generation). Retrieved contexts получен с помощью Retriever поверх Vector Store.
Предобученная LLM (например, ChatGPT) знает уже много — она обучалась на огромном корпусе данных: сайты, книги, коды, форумы, всё подряд. Но у такой модели есть одна большая проблема: Она не знает ничего про внутренний контекст компании: как у тебя считаются метрики, какие A/B тесты были, как устроены ключевые таблицы. Чтобы LLM могла использовать знания из своей компании — ей нужно их передавать.
Retriever — это компонент, который вытаскивает только релевантную информацию, может быть интегрирован с собственной базой знаний (PDF, CSV, SQL, Confluence и др.), и может работать с LLM на основе релевантного контекста. На сайте LangChain можно посмотреть более подробно про основные концепции Retrievers + вот тут посмотреть какие вообще реализованы у LangChain Пайплайн работы с Retriever 1. Загрузка документов (файлы, базы, статьи). Все, что мы считаем нужным для решения задачи. От черновиков дло 2. Разбиваем их на части (чанки) для индексации 3. Преобразуем текст в векторное представление (через эмбеддинги) 4. Сохраняем в векторную базу (Vector Store) — например, в FAISS или Chroma 5. По запросу — находим ближайшие куски текста, которые помогут модели ответить
Retriever делает семантический поиск по смыслу, а не просто по словам.
На LangChain можно реализовать достаточно быстро + покрутить эмбеддинги. Также советую от OpenAI ресурс, в котором можно посмотреть сколько токенов нужно для обработки вопроса (контекст мы также учитываем). Для апишки получается дешевле доставать релевантные данные с помощью ретривера и пулять дальше запрос.
`from langchain_community.document_loaders import TextLoader from langchain_community.vectorstores import FAISS from langchain_openai import OpenAIEmbeddings from langchain_text_splitters import CharacterTextSplitter from langchain.chains import RetrievalQA, ConversationalRetrievalChain
loader = TextLoader("text_for_gpt.txt") documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0) texts = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings() vectorstore = FAISS.from_documents(texts, embeddings) retriever = vectorstore.as_retriever()
llm = ChatOpenAI(model="gpt-3.5-turbo") qa_chain = RetrievalQA.from_chain_type(llm=llm, retriever=retriever) response = qa_chain.invoke({"query": 'О чем статья? Расскажи вкратце'})
print(response["result"])
Выше реализован single-shot RAG (одна проходка и ответ из базы). В дальнейшем напишу про виды RAG и чем они отличаются)
Какие бывают типы Retrieval? [статья с хабра]
1. Sparse Retrieval — классический полнотекстовый поиск Примеры: TF‑IDF, BM25 Базы: PostgreSQL (GIN), Apache Solr, Whoosh
2. Dense Retrieval — семантический поиск через нейросети Примеры: BERT, word2vec, e5-multilingual, OpenAI Базы: ChromaDB, FAISS, Pinecone, Qdrant, Milvus
3. Hybrid Retrieval — комбинация sparse + dense Примеры: ElasticSearch с плагином, Qdrant, PostgreSQL с pgvector
4. Graph Retrieval — поиск по графам знаний (use case: связи между объектами) Примеры: Neo4j, Weaviate, ArangoDB, TigerGraph.
Далее релевантно описать про дробление документа на чанки, все зависит от того, насколько вам заходит такие посты, ставьте реакции.
🤖 — Да, интересно читать про LLM, давай дальше!****🦜 — Давай лучше про A/B тесты (это бежит попугайчик LangChain)`