
30.04
Сбер представил первую на русском языке модель с нативным восприятием аудио
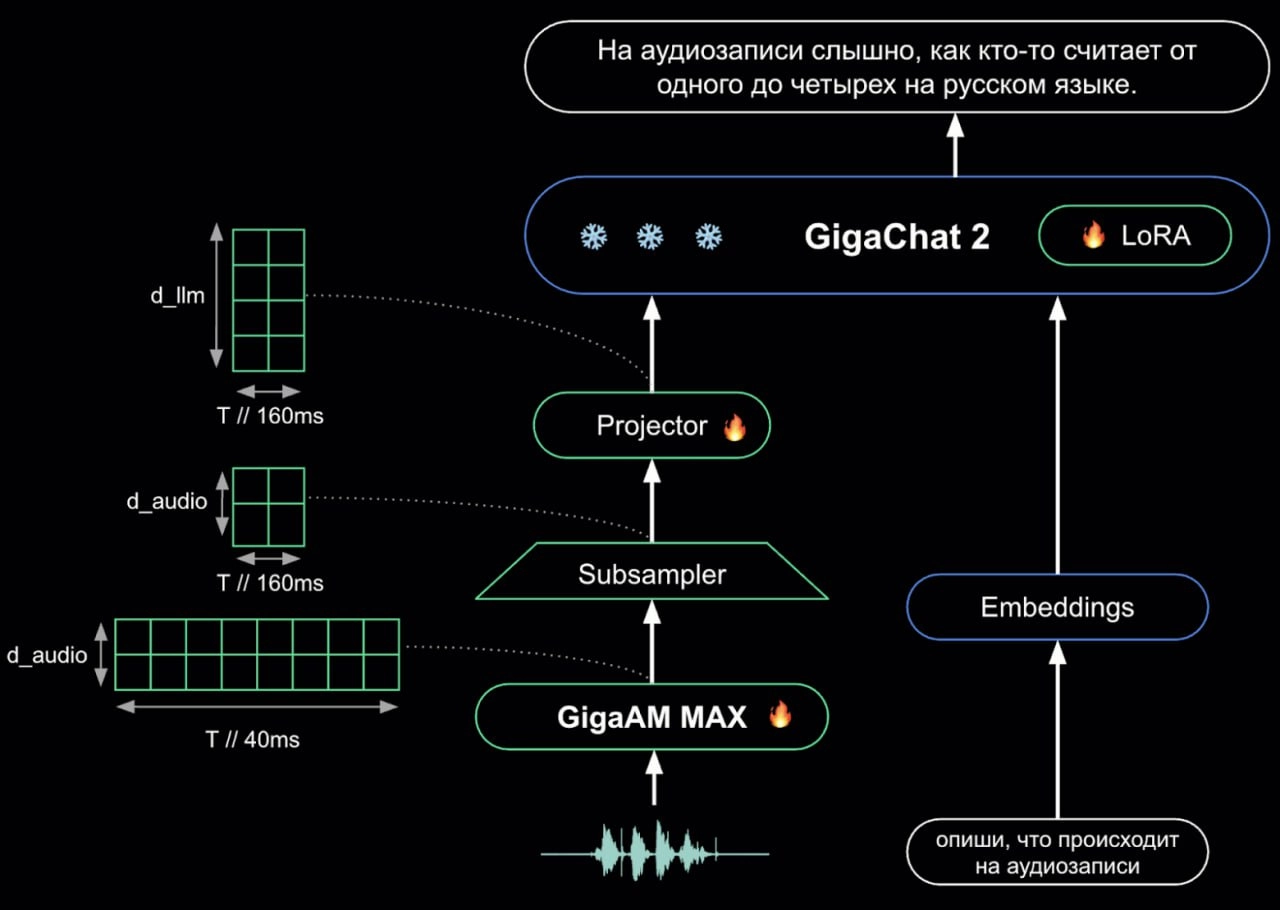
Тут прикрутили аудио-модель к GigaChat 2 LLM, то есть на вход можно подавать сразу и текст и звук, который преобразуется в токены и подаётся в LLM. Это примерно как в 4o, только пока без генерации аудио, но зато теперь есть полноценное понимание звука.
Моделька распознаёт эмоции и звуки, музыку и речь на других языках. Из фишек — длина контекста в 170 минут, хватит аж на две лекции подряд (привет студентам, как там диплом?). При этом базовые метрики упали, но незначительно.
Пишут, что скоро стоит ждать полноценную speech-to-speech модель. Тогда мы получим настоящий аналог 4o. И там уже можно закрывать все колл-центры в РФ. Ведь, как показала практика, боты куда эффективнее убеждают людей. А значит, они смогут лучше продавать.
@ai_newz
напишите коммент
еще контент в этом сообществе
еще контент в этом соообществе
30.04
войдите, чтобы увидеть
и подписаться на интересных профи
в приложении больше возможностей
пока в веб-версии есть не всё — мы вовсю работаем над ней
cоциальная сеть для нетворкинга от hh.ru
пересекайтесь с теми, кто повлияет на ваш профессиональный путь
сетка — cоциальная сеть для нетворкинга от hh.ru
пересекайтесь с теми, кто повлияет на ваш профессиональный путь