

PythonTalk
Олег Булыгин, Data scientist, аналитик, инвестор. Автор и спикер IT-курсов · 18.06
LLM всё ещё не могут в сложное программирование 🤖
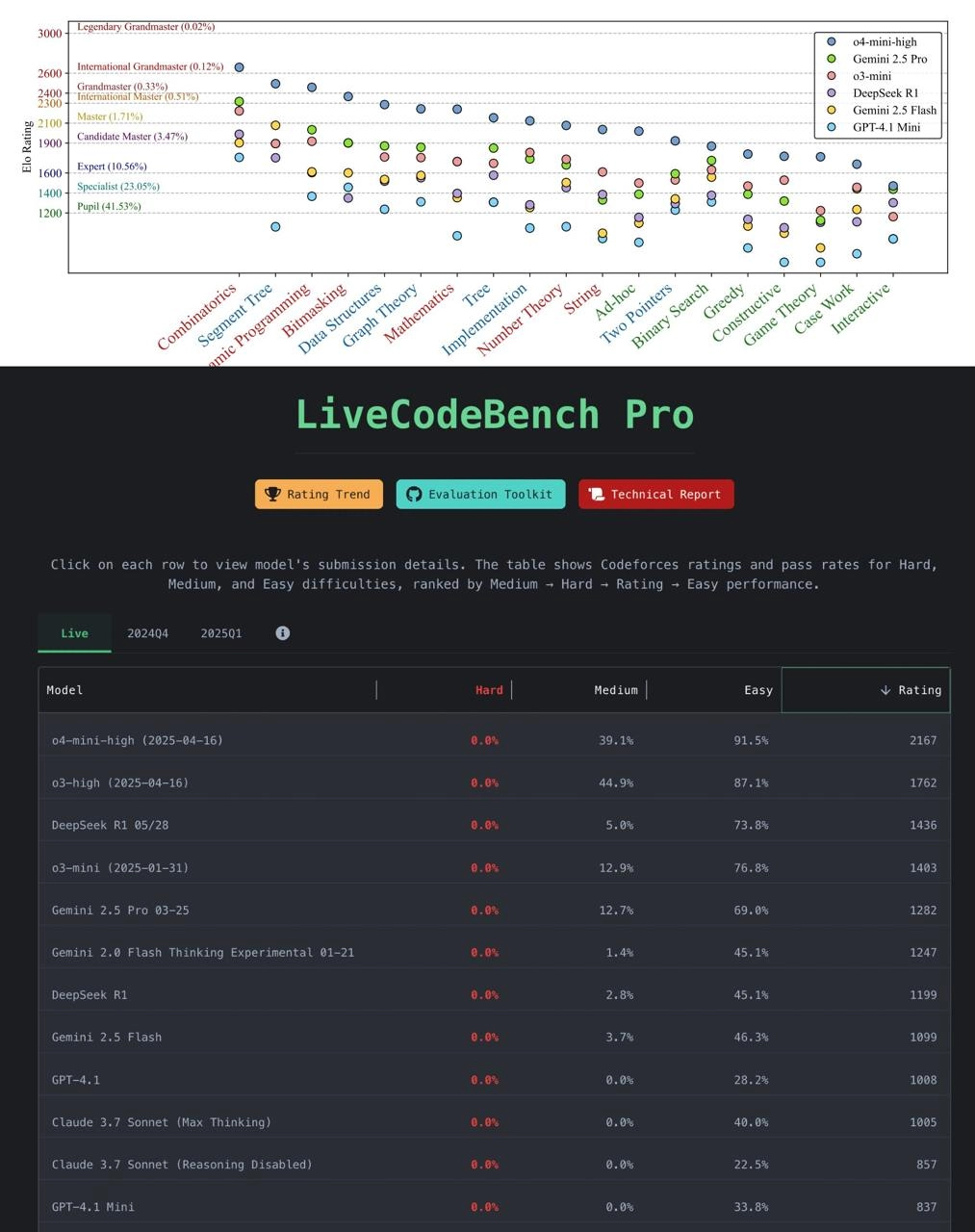
Тут выкатили новый бенчмарк LiveCodeBench Pro. Он состоит из самых свежих и сложных задач с Codeforces, ICPC и IOI. То есть никакого натаскивания на слитых в сеть решениях. Размечали задачи сами победители и призеры олимпиад.
Итоги печальные: 👉🏻 На сложных задачах все, абсолютно все модели получили 0%. Ноль. 👉🏻 Лучшая модель o4-mini-high набрала рейтинг ~2100. Это не более чем уровень крепкого эксперта. До гроссмейстеров (2700+) — как до Луны.
1️⃣ Где LLM хороши: На задачах, где нужны знания и шаблоны (комбинаторика, ДП, структуры данных). Это их зона комфорта. 2️⃣ А где провал: На задачах, где нужен креатив и "ага!-момент" (теория игр, хитрые случаи, жадные алгоритмы). Тут их рейтинг падает ниже 1500.
У людей ошибки обычно в реализации (опечатка, синтаксис). У моделей — в самой идее. Они часто уверенно генерируют абсолютно неверный алгоритм.
Так что тебя, username, пока не заменят. Но только если у тебя большой рейтинг в задачках 🌝
напишите коммент
еще контент автора
еще контент автора
PythonTalk
Олег Булыгин, Data scientist, аналитик, инвестор. Автор и спикер IT-курсов · 18.06
войдите, чтобы увидеть
и подписаться на интересных профи
в приложении больше возможностей
пока в веб-версии есть не всё — мы вовсю работаем над ней
cоциальная сеть для нетворкинга от hh.ru
пересекайтесь с теми, кто повлияет на ваш профессиональный путь
сетка — cоциальная сеть для нетворкинга от hh.ru
пересекайтесь с теми, кто повлияет на ваш профессиональный путь