

Поиск секретов в коде с помощью LLM
Исследователи Wiz пришли к выводу, что языковые модели лучше справляется с поиском секретов, чем традиционные регулярки. Исследователи команды GitHub тоже пришли к этому выводу, но только с помощью LLM.
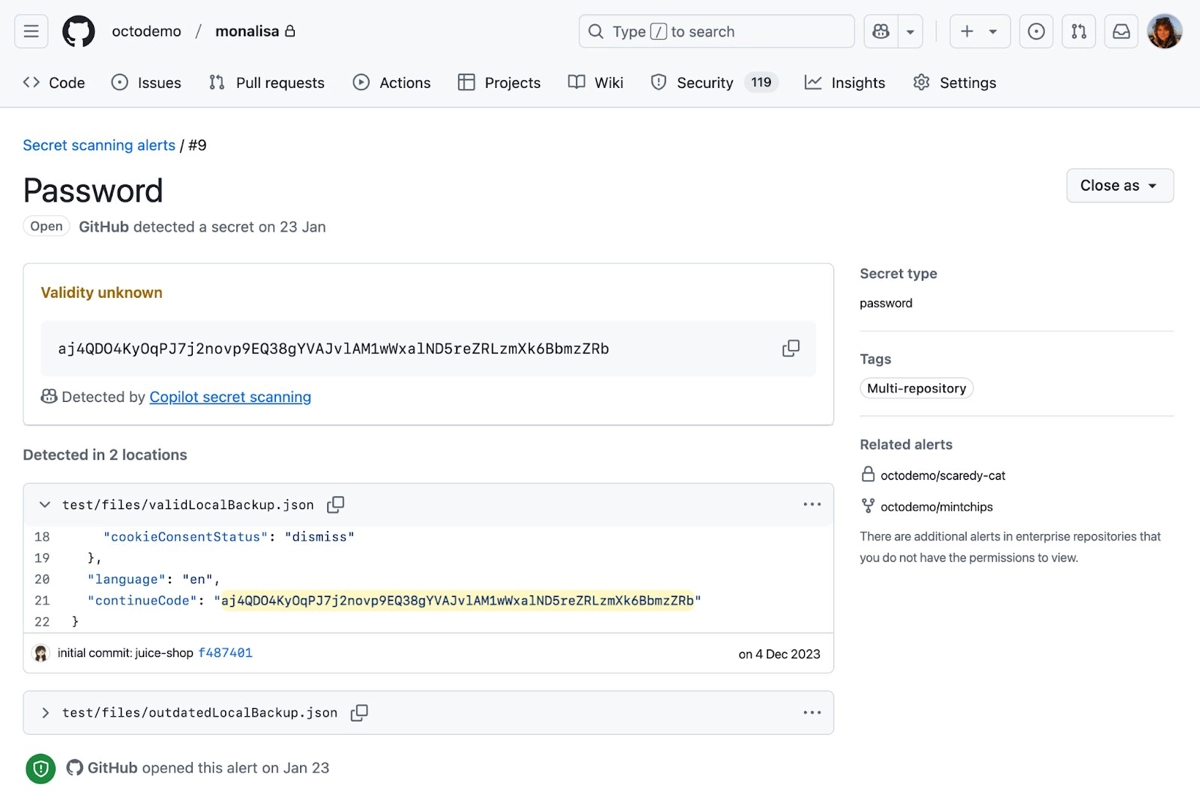
Обычные регулярки хороши только там, где формат строк строго определен (ключи, API-токены), но не учитывают многообразие структур строк паролей. LLM снижает количество шума, потому что учитывает контекст. Ожидаемо, использование LLM требует линейного увеличения вычислительных ресурсов с каждым новым клиентом. И чтобы сэкономить немного ресурса, команде пришлось исключить из проверок все медиафайлы или файлы, которые содержали в названии “test”, “mock”, “spec”.
Если занимаешься поиском секретов в репозиториях, то из исследования можно позаимствовать следующие инсайты: ⭐️ Регулярные выражения - это база для выявления детерминированных строк, но она сильно шумит при поиске паролей. ⭐️ LLM снижает шум и хорошо справляются с задачей поиска за счет анализа контекста. При этом использовать LLM для активных и крупных репозиториев - дорого. ⭐️ Чтобы экономить ресурсы можно выбрать два пути: сокращать размер базы для анализа (как GitHub) или оптимизировать использование вычислительных ресурсов для анализа (как Wiz). Еще лучше использовать оба подхода. ⭐️ Стратегии подсказок (промптов) для LLM влияют на точность обнаружения и на количество потребляемых ресурсов. GitHub попробовал стратегии Zero-Shot (дать модели только задачу, без примеров), Chain-of-Thought (попросить модель прийти к ответу через цепочку рассуждений), Fill-in-the-Middle (дать контекст “до” и контекст “после”, затем попросить дополнить середину) и MetaReflection (после первого ответа модели попросить ее проанализировать и доработать собственный ответ). В итоге MetaReflection дала лучшую точность.
напишите коммент
еще контент автора
еще контент автора
войдите, чтобы увидеть
и подписаться на интересных профи
в приложении больше возможностей
пока в веб-версии есть не всё — мы вовсю работаем над ней
cоциальная сеть для нетворкинга от hh.ru
пересекайтесь с теми, кто повлияет на ваш профессиональный путь
сетка — cоциальная сеть для нетворкинга от hh.ru
пересекайтесь с теми, кто повлияет на ваш профессиональный путь