
28.07
⚡Мы с командой опубликовали статью "NABLA: Neighborhood Adaptive Block-Level Attention"
Модели генерации видео сейчас развиваются стремительно — например, Veo 3, Seedance 1.0, Kling 2.1 показывают феноменальное качество следования запросу, визуала и динамики (а иногда даже поражают тем, как воспроизводят «физику» сложных движений и сцен). Однако как и во всех трансформерных архитектурах (а почти все серьёзные модели генерации видео сейчас являются диффузионными трансформерами), квадратичная сложность full attention остаётся узким местом, особенно при работе с видео высокого разрешения (HD, Full HD и выше) и большой продолжительности (10+ секунд). А ведь только такие видео сейчас хочет видеть искушённый пользователь 😁
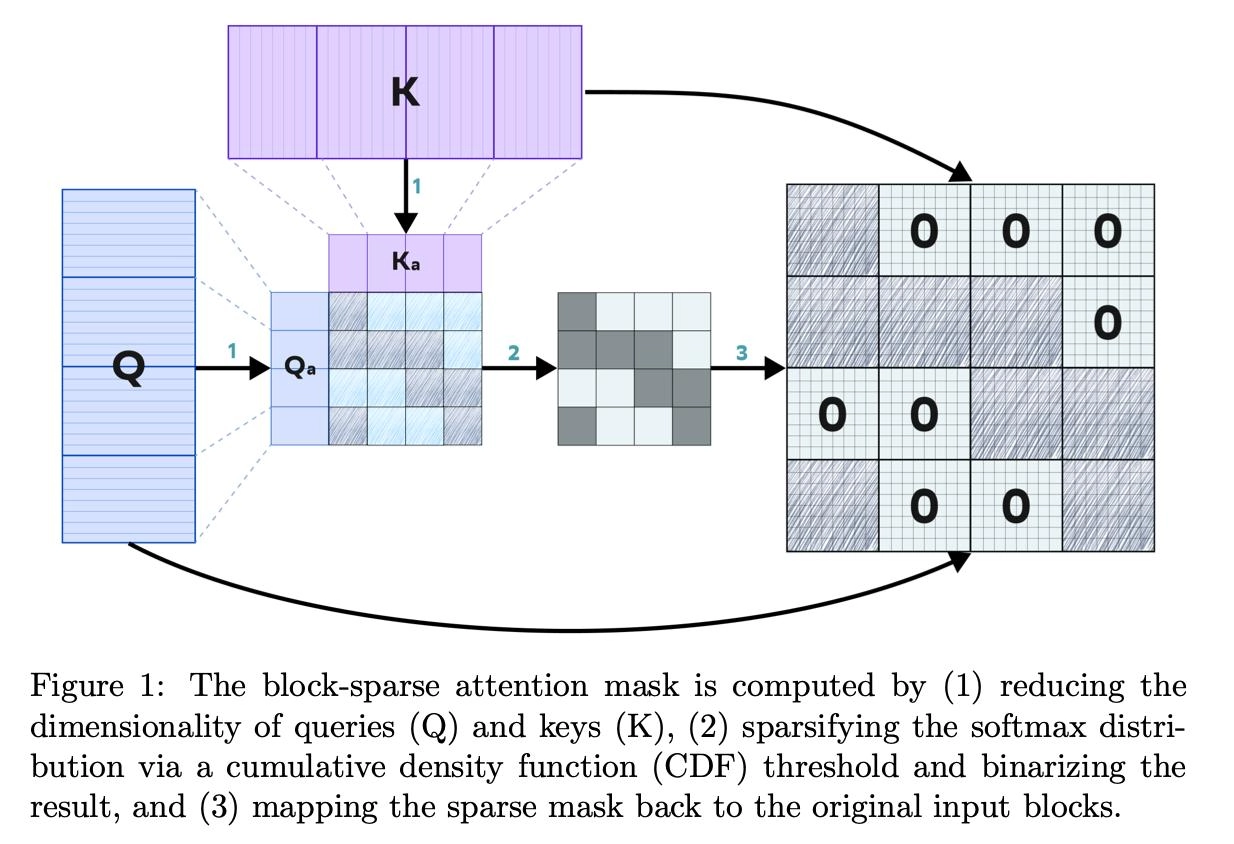
Наша статья предлагает новый механизм блочно-разреженного внимания для диффузионных трансформеров: вместо вычисления всей маски внимания (Full Attention) можно эффективно обнаружить только наиболее важные её блоки — и после этого вычисления производить только для них (при этом почти не «просадив», а на некоторых доменах даже улучшив качество всей модели). Алгоритм — на картинке в первом комментарии к этому посту (а подробности можно изучить в самой статье)
Экспериментально проверили, что метод позволяет ускорить инференс модели Wan2.1-T2V-14B (на текущий момент это одна из лучших открытых моделей генерации видео) почти в 3 раза при сопоставимых показателях качества (благодаря спарсификации 80-90%, практически без просадки по качеству). Также NABLA сильно бустит и обучение/инференс новой модели Kandinsky на высоких разрешениях — о чём напишу немного позже 😉
Что ещё важно: наш метод не требует написания специальных CUDA-ядер и полностью совместим с Flex Attention из PyTorch
Статью можно изучить на Hugging Face: https://huggingface.co/papers/2507.13546. А также сделать upvote, если статья показалась полезной — буду очень благодарен :)
напишите коммент
еще контент в этом сообществе
еще контент в этом соообществе
28.07
войдите, чтобы увидеть
и подписаться на интересных профи
в приложении больше возможностей
пока в веб-версии есть не всё — мы вовсю работаем над ней
cоциальная сеть для нетворкинга от hh.ru
пересекайтесь с теми, кто повлияет на ваш профессиональный путь
сетка — cоциальная сеть для нетворкинга от hh.ru
пересекайтесь с теми, кто повлияет на ваш профессиональный путь