

Финансовый аналитик в СберКорус
· 22.09SWE bench или кто прогает лучше ?
SWE-bench (Software Engineering Benchmark) — бенчмарк для оценки возможностей больших языковых моделей (LLM) в области автоматизированной разработки и отладки программного обеспечения. Кто не знает что это, коротко поясню.
Исследователи из Принстона взяли несколько открытых репозиториев и создали на их основе порядка 2000 задач на разных языках программирования. Затем, просто заставили модели их решать. Кто больше решил, тот молодец. Супер коротко, но суть понятна.
Сегодня я бы хотел рассказать о ребятах из Scale.AI. Что они сделали, подобрали задачи по сложнее. Да, 731 задача из публичных сетов. 858 отложили на потом, чтобы вылавливать те модели, которые специально будут обучать под первые 731 задачу. А еще допом подготовили 276 задач из приватных репозиториев, которые Scale.AI купили чтобы дать реальные задачи на сегодняшний день.
А в чем сложность то? В оригинальном swe bench, в среднем, требуют изменения 32,8 строчек кода в каждой задаче ( в очищенной OpenAI версии вообще 14.33 строки), в задачах Scale.AI - 107 строк. Теперь знайте, на что стоит рассчитывать, если собираетесь править код :)
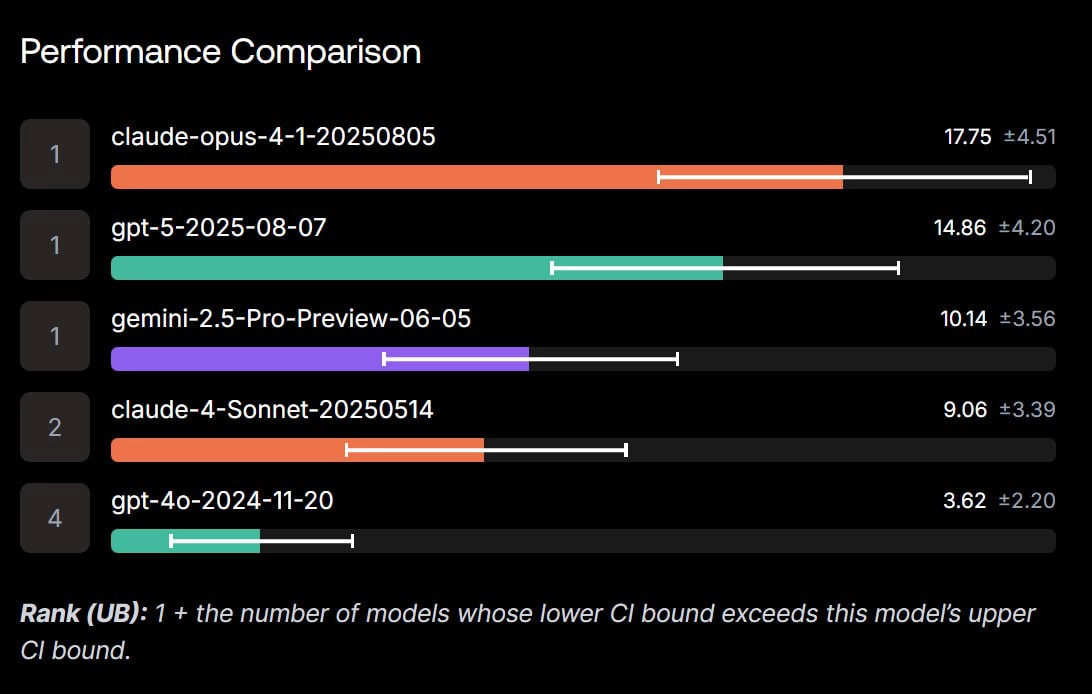
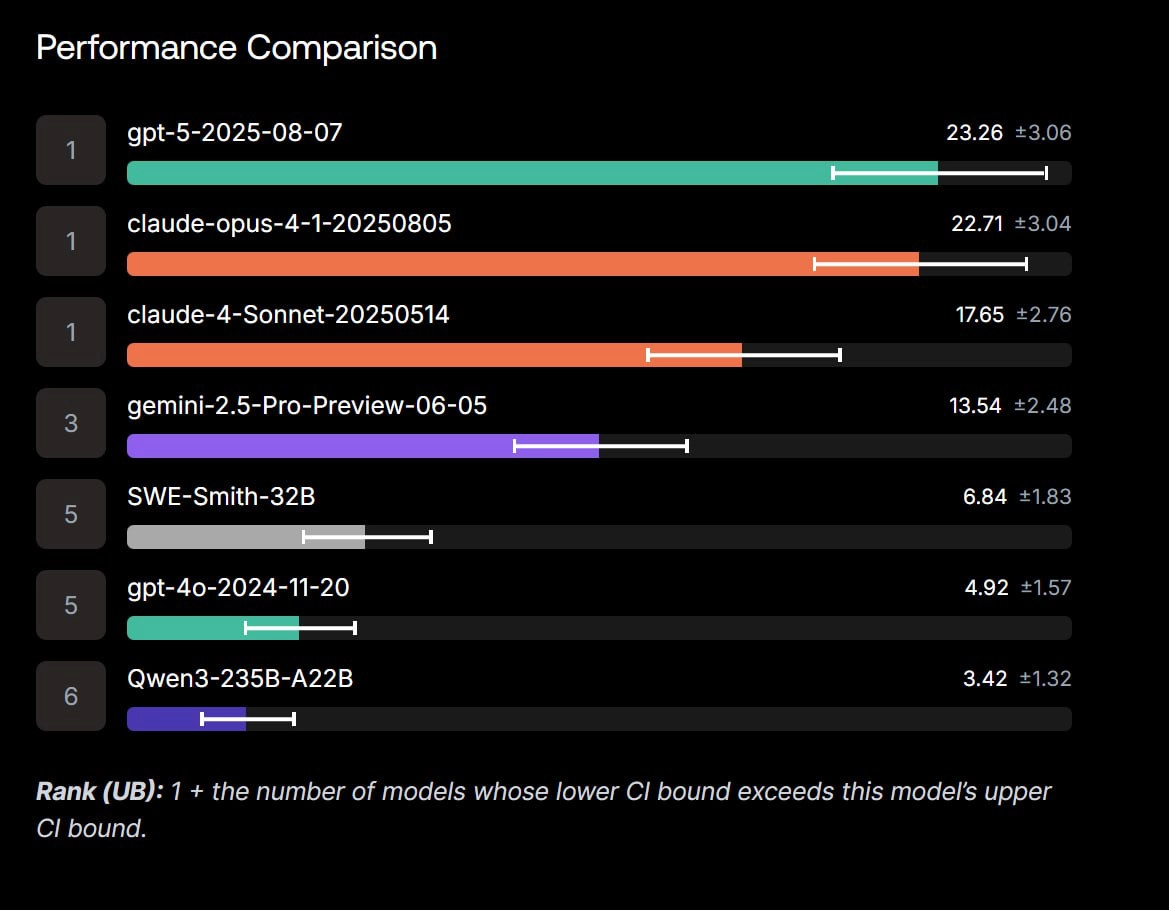
Результаты видны на скринах: 1 - Коммерческий датасет 2 - Публичный датасет
Да, видно, что что модели OpenAI и Anthropic находятся в лидерах. Коммерческий (купленный) датасет не сильно большой, поэтому разница в показателях может несильно. Проверяйте своих любимчиков )
напишите коммент
0 комментов
еще контент автора
cоциальная сеть для нетворкинга от hh.ru
пересекайтесь с теми, кто повлияет на ваш профессиональный путь
сетка — cоциальная сеть для нетворкинга от hh.ru
пересекайтесь с теми, кто повлияет на ваш профессиональный путь