📈Распределения: что такое нормальное распределение и почему оно важно (6/15)
Когда мы говорим о данных, понимание их распределения — это фундамент для правильного анализа и принятия решений. Представьте себе, что вы измеряете рост группы людей. Скорее всего, большинство будут иметь рост около среднего значения, а очень высоких и очень низких — гораздо меньше. Если нарисовать график количества людей с разным ростом, получится так называемая «колоколообразная кривая» — классический пример нормального распределения.
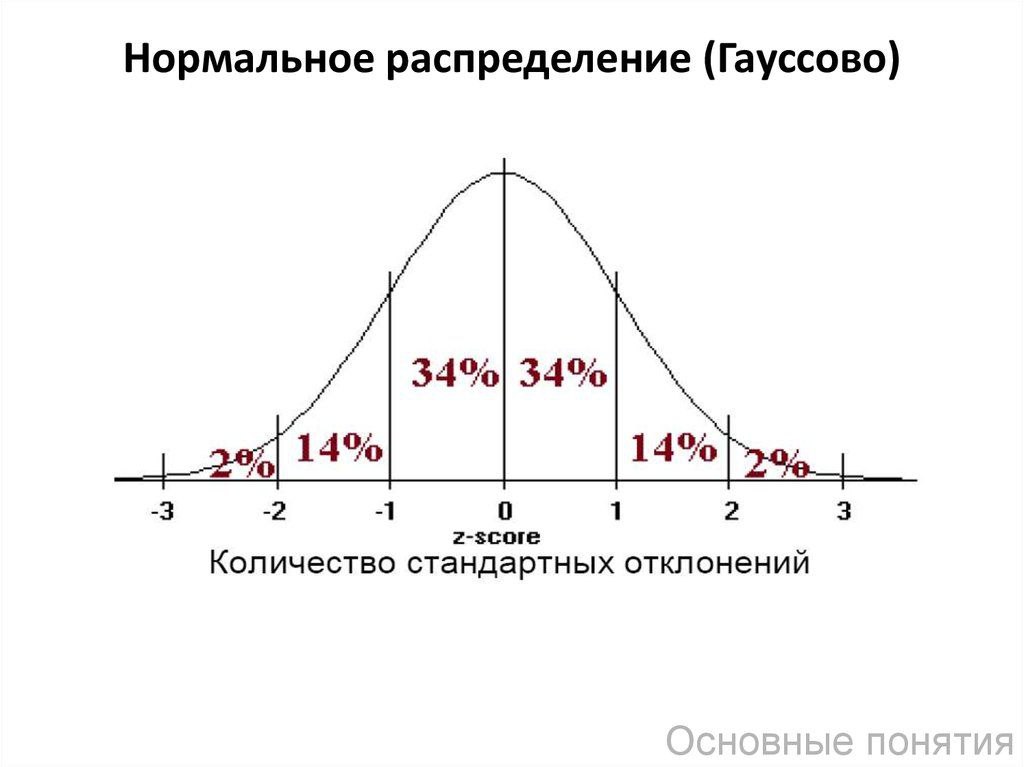
Нормальное распределение — это такое распределение вероятностей, где данные симметрично сгруппированы вокруг среднего значения, а вероятность появления значений далеко от центра резко падает. Визуально это выглядит как колокол: пик в центре, плавно спадающий к краям. Многие природные и социальные явления подчиняются именно этому распределению — например, IQ, рост, вес, ошибки измерений и даже некоторые финансовые показатели.
Почему это важно для аналитика? Во-первых, почти все классические статистические тесты, которые мы используем для проверки гипотез, рассчитаны на нормальное распределение данных. Если данные сильно отклоняются от нормального распределения, результаты тестов могут быть неверными или вводить в заблуждение. Например, при оценке эффективности рекламной кампании мы можем проверить, насколько выросла конверсия, используя t-тест, который предполагает, что данные распределены нормально.
Во-вторых, знание свойств нормального распределения помогает лучше понимать данные. Допустим, средний доход сотрудников компании — 50 000 рублей, а стандартное отклонение — 5 000. По правилу трёх сигм, примерно 99.7% сотрудников получают зарплату в диапазоне от 35 000 до 65 000 рублей. Если кто-то получает 100 000, это уже явный выброс, который стоит изучить отдельно.
Реальные примеры нормального распределения встречаются повсюду. Например, в производстве деталей на заводе размеры изделий часто распределены нормально. Это значит, что большинство деталей имеют стандартный размер, а слишком большие или слишком маленькие — редкость. Такой анализ помогает контролировать качество и своевременно обнаруживать проблемы.
Однако не все данные подчиняются нормальному распределению. Например, распределение количества покупок на сайте чаще всего сдвинуто вправо — большинство пользователей покупают мало, а небольшая часть — очень много. В таких случаях применяют другие методы и трансформации данных.
В следующих постах мы подробно разберём, как проверять, нормально ли распределены ваши данные, и что делать, если это не так. А пока запомните: понимание распределений — это ключ к тому, чтобы ваши данные говорили правду, а не путали вас.
Запомните, даже самый спокойный медведь умеет рычать, когда надо. Берегите голову, берегите данные — и пусть в вашем дне будет немного тишины, ясности и добрых переменных.
В этом посте были ссылки, но мы их удалили по правилам Сетки