Основные ограничения LLM моделей
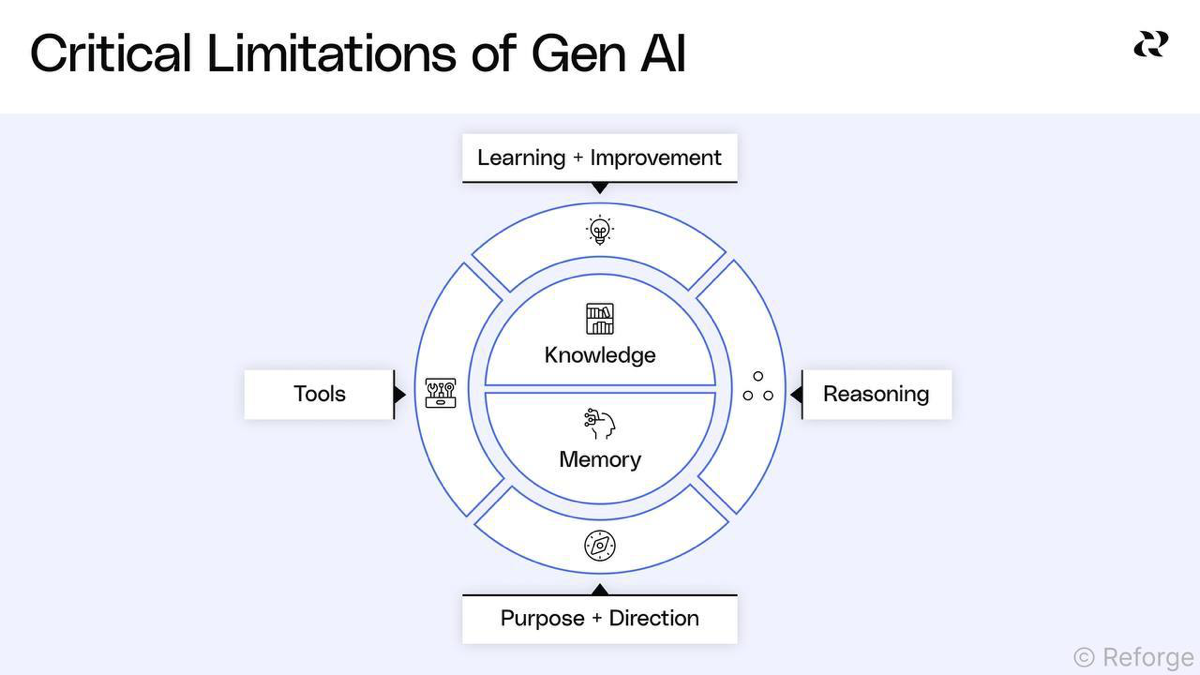
1. Знания (knowledge). LLM похожа на поезд, который прокладывает себе путь по рельсам, самостоятельно выбирая каждый следующий отрезок. Она не «видит» на несколько шагов вперед, а лишь предсказывает следующее слово по вероятностям, вычисляемым на основе косинусного расстояния между векторами в эмбеддинг-пространстве.
2. Память (memory). Контекстное окно ограничено, а с его расширением значительно увеличивается стоимость обработки (inference). Например, с ростом памяти в 2 раза стоимость compute (обработка операции в токенах) увеличивается в 4 раза. Позитивный тренд: за последние 2 года стоимость вычислений существенно снизилась—в 240 раз (например, обработка 2 млн токенов в GPT упала со $180 до $0,75)
3. Мышление/ризонинг (Reasoning). Если у человека, согласно Канеману, есть два типа мышления — быстрое и медленное, то у LLM фактически есть только быстрое. И хотя последние модели (o3, claude Opus, gemini 2.5) сделали значительный шаг вперед, “глубокого” или медленного мышления у LLM пока нет.
4. Способность к обучению. LLM не учится непосредственно на корректировках пользователя, не запоминает отраслевые термины и не адаптируется под предпочтения. Для решения этих задач в коммерческом использовании есть отдельные инструменты: RAG (поиск и подгрузка контекста), fine-tuning (тонкая настройка моделей), и другие (классический ML)
5. Инструменты (tools). LLM ограничены в возможностях взаимодействия с внешними данными, средами и инструментами повседневных задач. Для решения этой проблемы используются протоколы, такие как MCP, или агентские фреймворки, например, A2A.
6. Понимание цели и контекста. Несмотря на хороший промпт, LLM теряет контекст и не способна отвечать/решать задачу эффективно держа в фокусе цель запроса. Например, для решения бизнес-задачи, она может давать пул нерелевантных метрик из-за поверхностного анализа и слабой приоритизации, т.к она теряет контекст главной цели и понимание задачи
Больше постов здесь: https://t.me/ilya_eli_blog