Топ-5 LLM-лидеров по результатам бенчмарков (октябрь 2025)
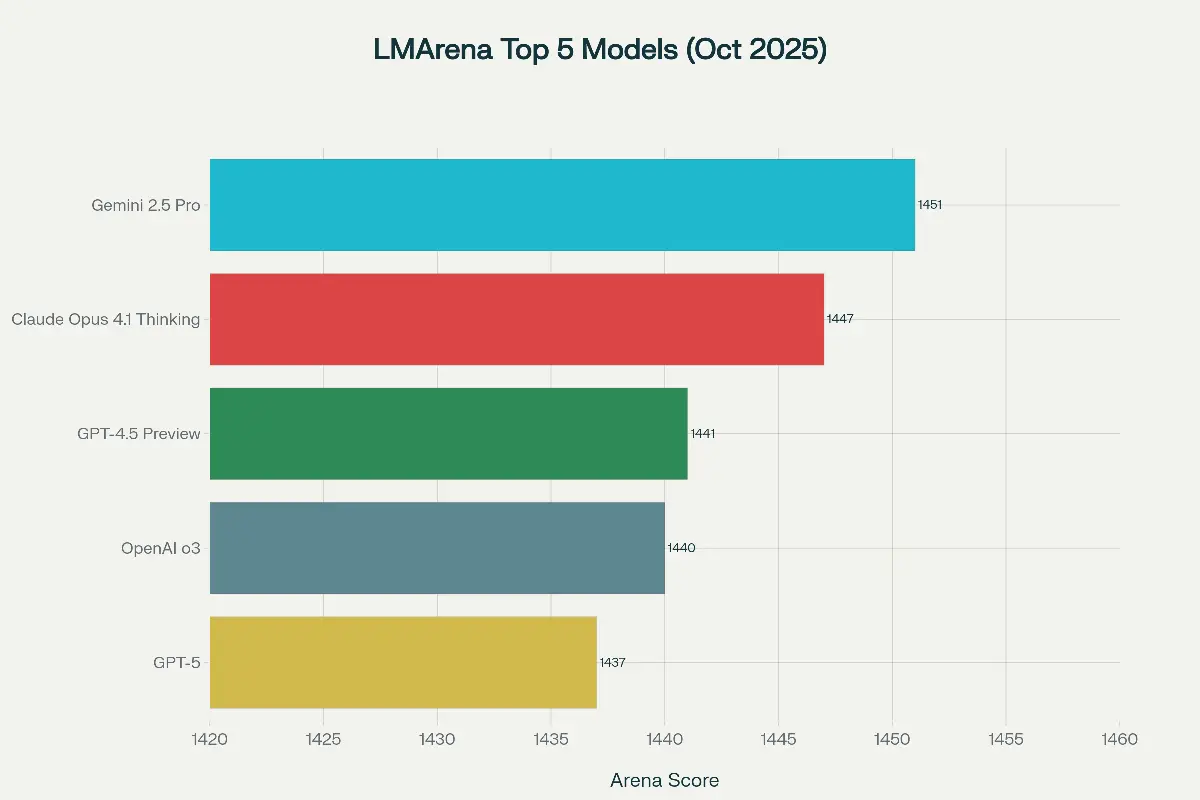
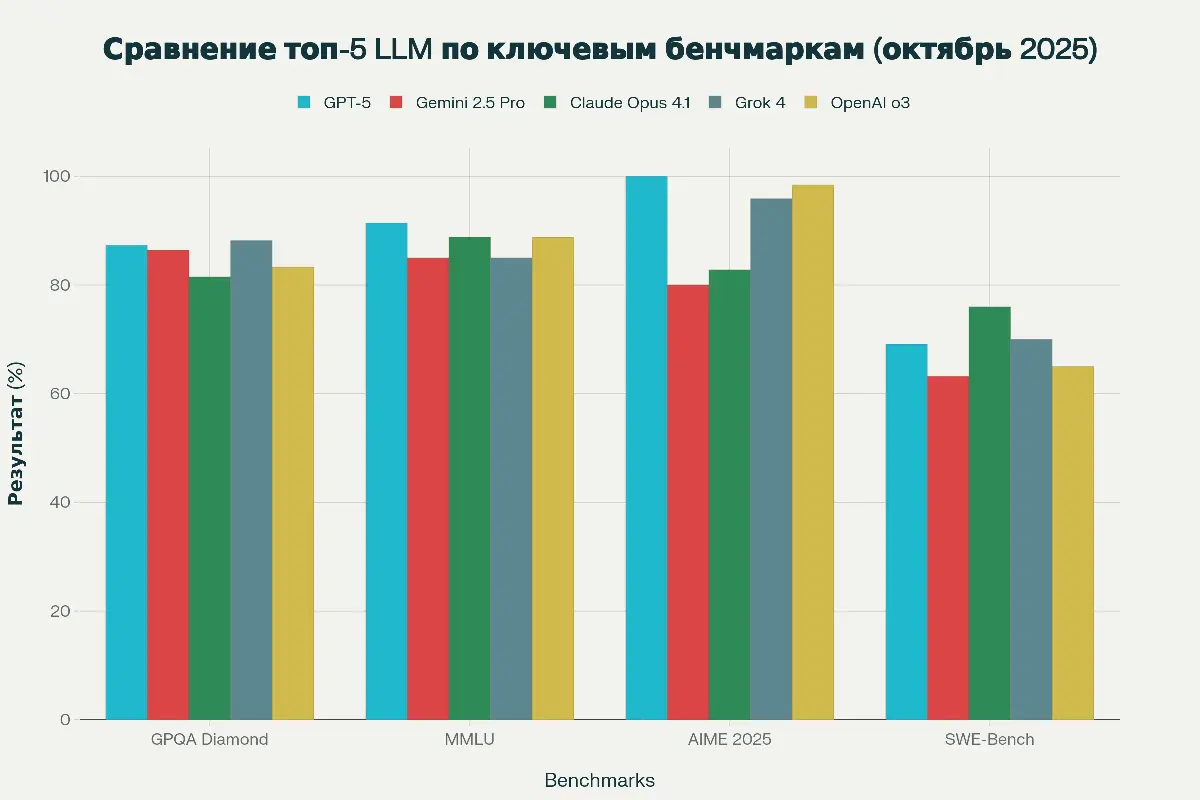
1. Gemini 2.5 Pro (Google DeepMind) Gemini 2.5 Pro лидирует в общем пользовательском рейтинге LMArena с оценкой 1451 балл, утвердившись как наиболее сбалансированное и универсальное решение. Модель предлагает лучшее соотношение цены и качества, превосходную мультимодальную обработку и впечатляющее контекстное окно в 1 миллион токенов. Она показывает сильные результаты в сложных научных задачах (86.4% на GPQA Diamond). 2. GPT-5 (OpenAI) Выпущенный в августе 2025 года, GPT-5 устанавливает новый стандарт в области точности и математического рассуждения. Модель демонстрирует 100% результат на AIME 2025 (математическая олимпиада высокого уровня) и значительно снижает число галлюцинаций (на 26% меньше, чем GPT-4o). С результатом 1437 баллов на LMArena, GPT-5 — выбор для задач, требующих глубокого анализа и многошагового рассуждения. 3. Claude Opus 4.1 (Anthropic) Claude Opus 4.1, представленный в августе 2025 года, является безусловным лидером в программировании. В режиме высокой вычислительной мощности модель достигает 79.4% на SWE-bench Verified — золотом стандарте для реальных задач разработки ПО. Это делает ее идеальным инструментом для разработки программного обеспечения, рефакторинга кодовых баз и построения автономных агентных систем. 4. Grok 4 (xAI) Grok 4 от xAI, обученный на суперкомпьютере Colossus, специализируется на научном рассуждении и бизнес-анализе. Модель лидирует в академических тестах PhD-уровня: 88.9% на GPQA Diamond. В мультиагентной конфигурации Grok 4 добился рекордного результата 50.7% на Humanity's Last Exam — самом сложном бенчмарке, требующем широких знаний и глубокого анализа. 5. OpenAI o3 OpenAI o3, выпущенный в апреле 2025 года, фокусируется на глубоком логическом мышлении за счет усиленного test-time compute (способности итеративно рассуждать перед ответом). Модель показывает высокую точность в сложных математических задачах с результатом 98.4% на AIME 2025 и является оптимальным выбором для задач, где приоритетом является минимальное количество ошибок. Ключевые тенденции LLM-индустрии 1. Специализация. Разрыв между моделями в общих тестах минимален. Лидеры отрасли четко фокусируются на сильных сторонах: Claude — на коде, GPT-5 — на математике, Grok 4 — на науке, Gemini — на контексте. 2. Насыщение бенчмарков. Традиционные тесты (MMLU, HumanEval) достигают потолка: топовые модели показывают свыше 90%. Индустрия активно переходит к более сложным и неконтаминированным бенчмаркам, таким как Humanity's Last Exam, где даже лучшие модели показывают лишь около 50%. 3. Test-Time Compute. Увеличение вычислительных ресурсов во время инференса (test-time compute) стало ключевым фактором для повышения производительности в задачах, требующих сложного рассуждения (например, в o3 и Grok 4), хотя это увеличивает стоимость и время ответа.
· 19.10.2025
Gemeni "эффект Джина" ловит часто, достаточно стека gpt-5, opus, grok
ответить
коммент удалён
· 19.10.2025
....представление о "темном знании"))) отдельная тема
ответить
ответ удалён