🚀 Ray Serve LLM анонсировал API для MoE и disaggregated-сerving
Появились новые API для удобного развертывания LLM с поддержкой wide-EP и disaggregated prefill/decode.
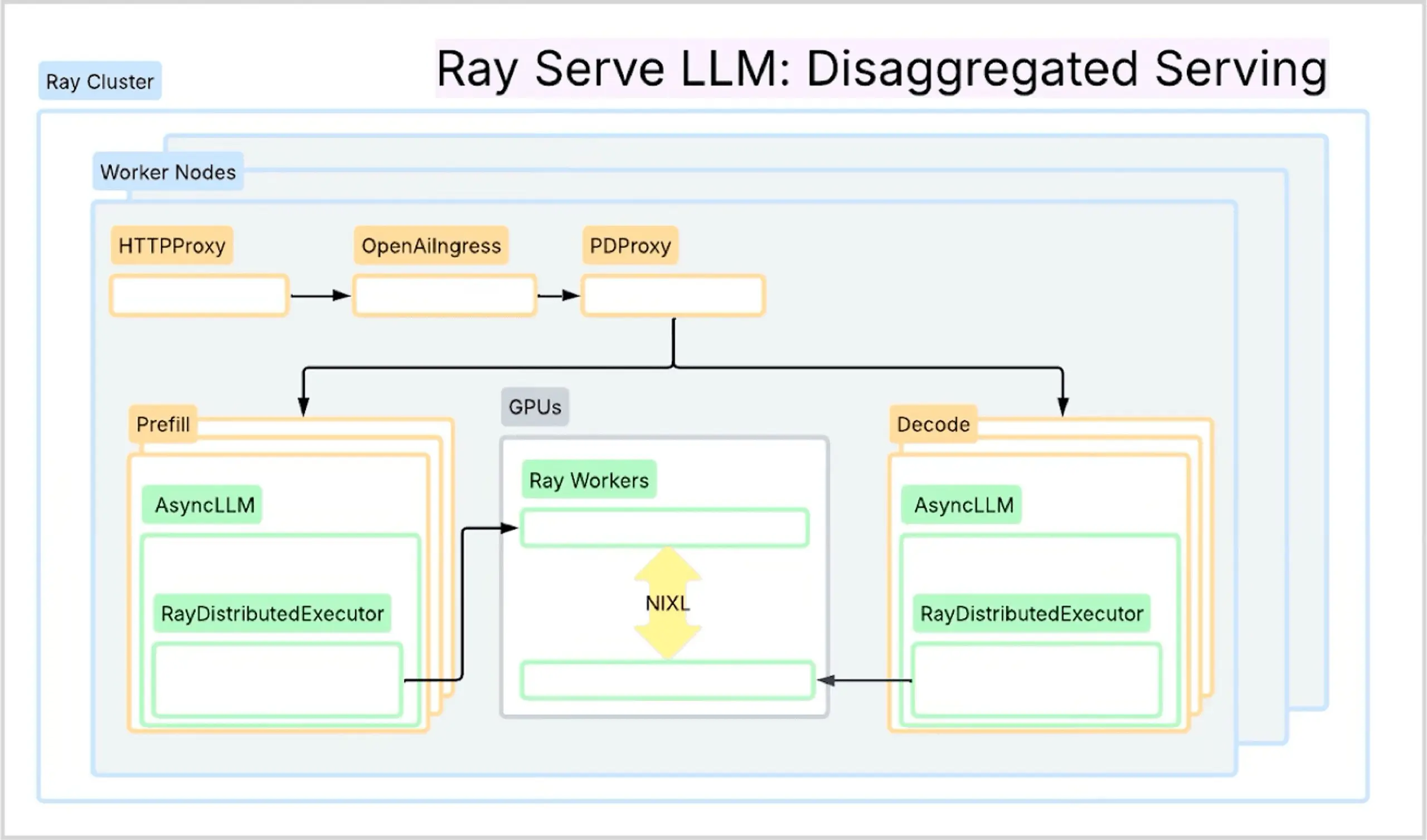
Ray Serve LLM теперь позволяет легко развертывать сложные архитектуры вроде wide expert parallelism (MoE) и разделения prefill/decode фаз. Это критично для эффективного инференса современных моделей типа DeepSeek и Qwen3. API автоматизируют создание группы данных, согласование рангов GPU, настройку vLLM с DeepEP и передачу KV-кеши через NIXL. Вся оркестровка — через Python, без YAML и ручной настройки.
Достигнута пропускная способность до 2.4K tps/H200 на Infiniband. Графы исполнения строятся из компонентов: build_dp_deployment для wide-EP и build_pd_openai_app для disaggregation. Поддержка кэш-ориентированной маршрутизации повышает hit rate и снижает задержки.
#ray_serve #vllm #llm_serving #moe #disaggregated_serving #anyscale