🚀 MoE-архитектура ускоряется в 10 раз на Blackwell
NVIDIA показала, как архитектура Mixture of Experts (MoE) достигает 10-кратного прироста производительности на платформе GB200 NVL72.
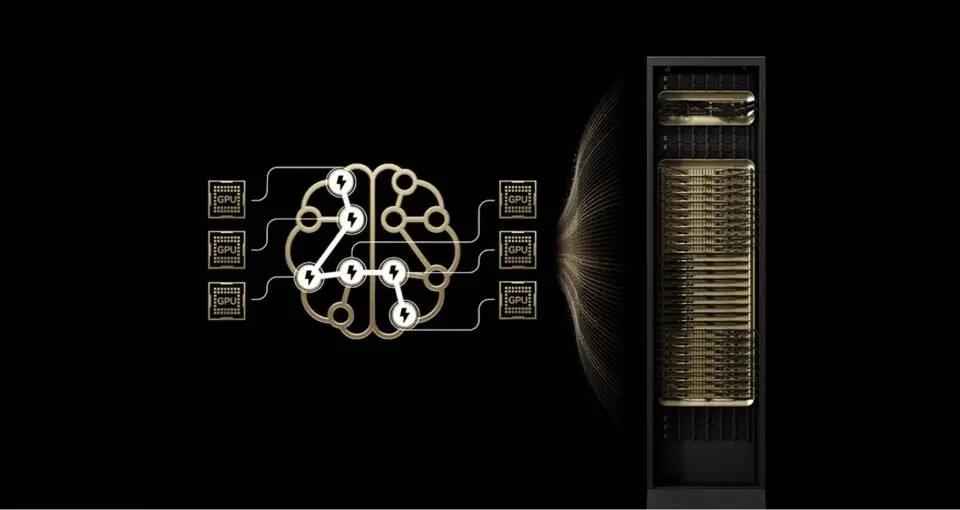
MoE-модели дробят задачи между специализированными «экспертами», активируя только нужные для каждого токена — как мозг решает разные задачи разными участками. Это резко снижает вычислительную нагрузку. На GB200 NVL72 с 72 GPU и 30 ТБ общей памяти эксперты распределяются по всей системе через NVLink с пропускной способностью 130 ТБ/с. Так устраняются узкие места: меньше нагрузки на память каждого GPU и мгновенная коммуникация между экспертами. Поддержка TensorRT-LLM, SGLang и NVFP4 усиливает эффективность.
Кими K2, DeepSeek-R1 и Mistral Large 3 показали рост в 10 раз по токенам/сек на GB200 по сравнению с H200. Такой прорыв снижает стоимость токена и энергопотребление, делая MoE стандартом для фронтальных моделей.