В продолжение темы автономных систем решающих сложные задачи.
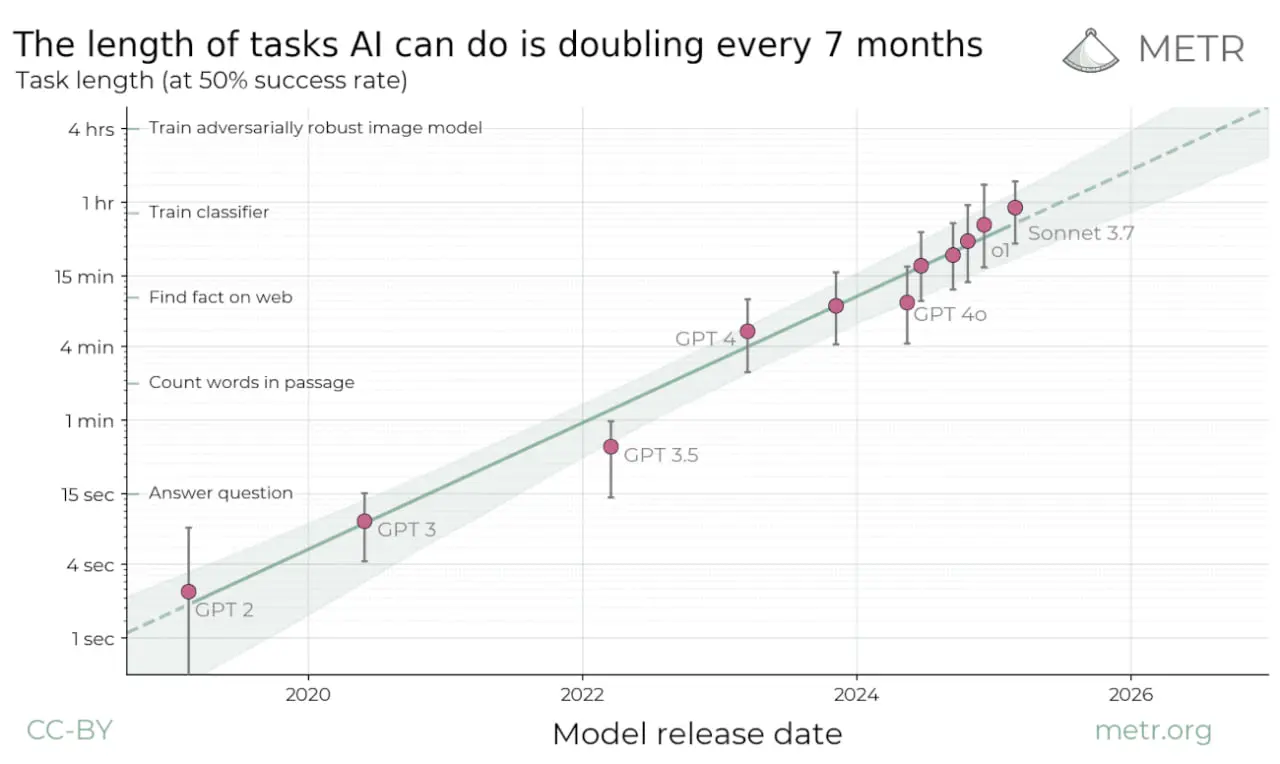
Хороший подход для измерения вопроса предлагает бенчмарк METR
Ребята взяли задачи для которых известно сколько времени тратит на них профессионал. И дальше замеряют какой длины задачи могут стабильно решать AI-системы. Задачи в-основном про разработку и ML.
Так вот, длительность стабильно решаемых задач удваивается в среднем каждые 7 месяцев. И это довольно старый тренд, ещё с 2020 года.
В новостях про этот бенчмарк часто пишут что "Claude Opus 4.5 пробил уже 4 часа", но это результат с вероятностью 50%. Это так себе инженер 🤡 Если взять 80% успеха, то Opus 4.5 пробил только 27 минут. И вот это похоже на честный текущий максимум: задачи человеческой сложностью в полчаса модели решают достаточно надежно сами.
Однако, тренд это не отменяет. Если тренд продолжится, через 3-5 лет задачи уровня написания браузера будут решаться автономно. Так же как и задачи уровня "построить маркетплейс", "создать банковское приложение", you name it.
Trust the trendline Почитать можно тут