
Как научить машину понимать смысл слов
Я думаю все вы слышали про векторные базы данных. В прошлом посте обещал поделиться статьёй про то, как же слова и целые тексты превращаются в вектора.
«Привет! Я [0.44, -0.91, 0.66…]» или как научить машину понимать смысл слов
В машинном обучении есть базовое правило: модель умеет работать только с числами. Поэтому любой объект — текст, картинку, звук — сначала нужно превратить в числовое представление. Только тогда модель сможет понять, что «груша» связана с «яблоком» куда больше, чем с «теплоходом»
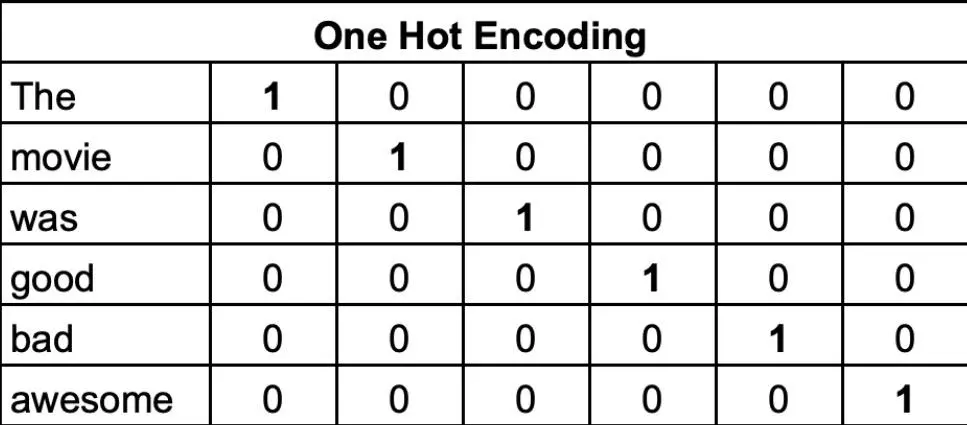
Самый простой вариант для текста — 🔢 one hot encoding.
Мы берём словарь и каждому слову ставим в соответствие вектор, где одна позиция равна 1, а все остальные — 0.
Возьмём предложения:
1. The movie was good. 2. The movie was bad. 3. The movide was awesome.
Кодировка на первой картинке.
Формально задача решена, но есть проблема: такие векторы ничего не говорят о смысле слов. Для модели слова «кот» и «собака» так же не похожи друг на друга, как «кот» и «кирпич».
Плюс векторы получаются «разреженными» — огромными и почти полностью заполненными нулями. Ну и, конечно, это потребует большого количества ресурсов для обработки.
👉 Следующий шаг — мешок слов и N-граммы. Мы начинаем учитывать не отдельные слова, а их последовательности.
Кодировка на второй картинке.
Но N-граммы смотрят только на ограниченное число слов и строго по порядку. Поэтому они не улавливают более глубокие смысловые связи.
В реальности таких возможных N-грамм — тысячи, и большая часть значений всегда равна 0. То есть, проблема разреженных векторов полностью не уходит.
Чтобы модель работала лучше, ей нужно понимать семантику и контекст. Здесь и появляются 🔡 word embeddings.
Эмбеддинг — это плотный числовой вектор фиксированной размерности, почти без нулей. Идея в том, что похожие по смыслу слова имеют похожие векторы, а направление в векторном пространстве несёт смысл.
В статье это объясняется на наглядном примере с животными. - Сначала берётся одно измерение — размер. Животные с похожими габаритами находятся рядом. - Затем добавляется второе измерение — хищность. В таком пространстве 🦁 «лев» и 🐯 «тигр» оказываются близко (крупные и опасные), 🐄 «корова» — отдельно (крупная, но безопасная), а 🐹 «хомяк» — совсем в другой области.
Когда слова представлены такими векторами, с ними можно выполнять математические операции:
V(Madrid) + V(Germany) − V(Spain) ≈ V(Berlin)
если мы возьмём слово «Мадрид», добавим «Германия» и вычтем «Испания», ближайшим полученным словом будет «Берлин». Это работает, потому что Мадрид — столица Испании. Когда мы убираем атрибуты, связанные с Испанией, и добавляем атрибуты, связанные с Германией, результирующий вектор тесно совпадает с Берлином, столицей Германии.
Сами эмбеддинги генерируются с помощью специально обученных моделей. Ну а про сам подход генерации лучше почитать непосредственно в стать.
❤️ — если интересно читать про эмбеддинги и ИИ

· 13.02
https://t.me/cherkashindev/435
ответить
коммент удалён