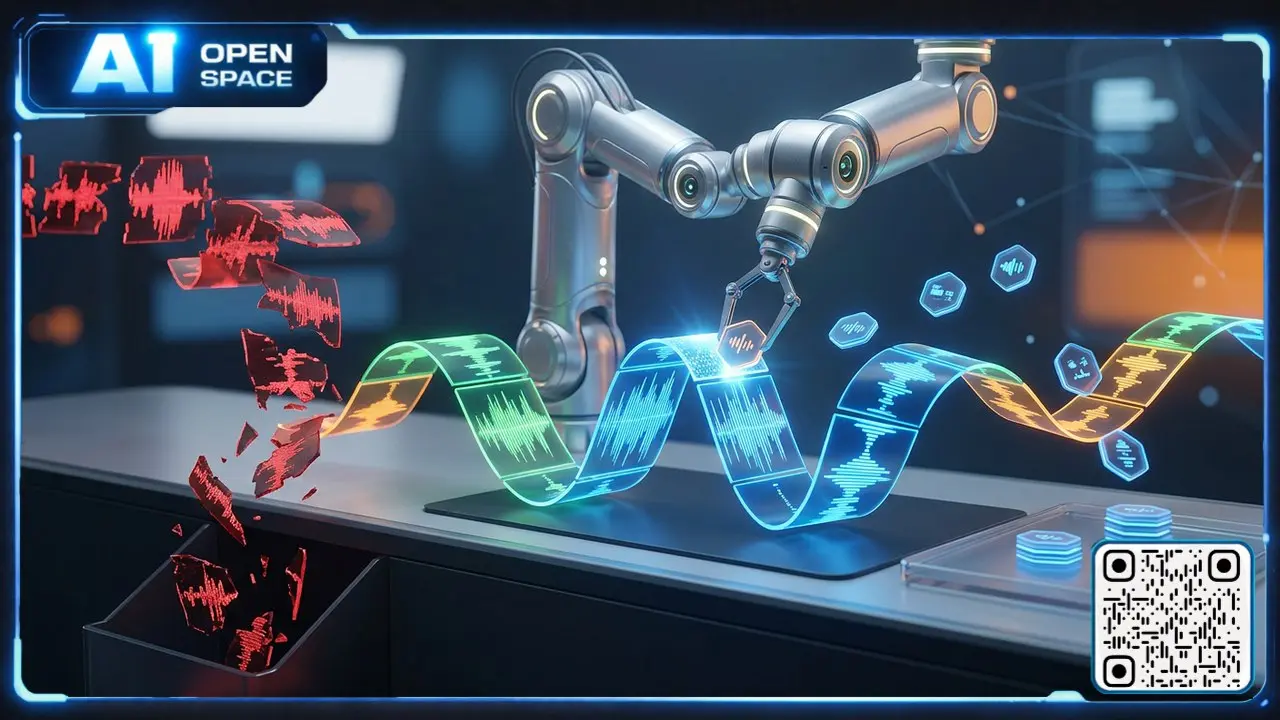
Модель WAVe‑1B проверяет синтетическую речь по словам
WAVe‑1B Multimodal оценивает качество синтетической речи на уровне отдельных слов — это позволяет отфильтровать плохие данные перед обучением ASR и сократить затраты на тренировку моделей.
Модель объединяет аудио и текстовые эмбеддинги: текст обрабатывает XLM‑RoBERTa, аудио — Wav2Vec2‑BERT 2.0, а модуль выравнивания на multi‑head attention и GLU сопоставляет слова с аудиосегментами. Такой подход выявляет ошибки произношения, тайминга и просодии, которые пропускают sentence‑level фильтры. По данным автора, при обучении португальского ASR это снижало число шагов обучения и уменьшало объём синтетических данных.