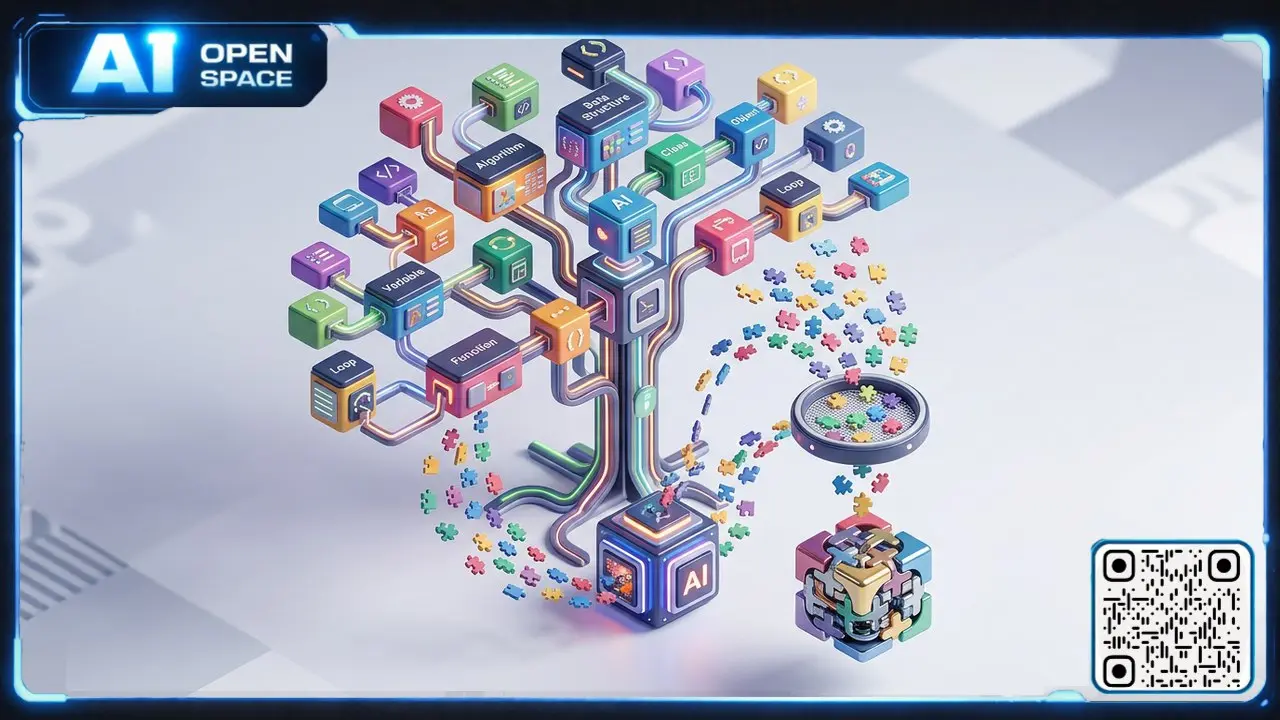
NVIDIA показала, как синтетические задачи улучшают код‑LLM
Синтетический датасет из ~15 млн задач по Python дал +6 пунктов на HumanEval для Nemotron Nano v3. Для разработчиков это сигнал: точечная генерация данных по концептам может быть эффективнее простого наращивания корпуса — стоит экспериментировать с концепт‑ориентированным синтетическим претрейном.
Датасет Code Concepts построен на таксономии тысяч программных концептов — от строк и рекурсии до алгоритмов и структур данных. Исследователи выбрали 91 концепт, связанный с задачами HumanEval, и сгенерировали задачи через LLM, затем валидировали код через Python AST. В финальный этап претрейна модели добавили около 10 млрд токенов этих данных. Датасет и таксономия выложены под CC‑BY‑4.0 и могут использоваться для таргетированного обучения моделей.
🔗 https://huggingface.co/blog/nvidia/synthetic-code-concepts
#LLM #SyntheticData #CodeGeneration #NVIDIA #MachineLearning