📦 Cgroups: невидимый диспетчер ресурсов
Кратко: cgroups (control groups) — это механизм ядра Linux, который ограничивает, учитывает и изолирует ресурсы (CPU, память, диск, сеть) для групп процессов. Без cgroups не было бы ни Docker, ни Kubernetes, ни современной контейнеризации. Это «квота» для процессов, которая не даёт одной программе сожрать весь сервер.
▫️Как дошли до жизни такой · 2006–2007 гг. — Инженеры Google (Paul Menage, Rohit Seth) разрабатывают «process containers» для внутренних нужд. Позже переименовывают в cgroups, чтобы избежать путаницы с контейнерами · 2008 г. — Первая версия cgroups v1 вливается в ядро Linux 2.6.24. Появляются подсистемы: cpu, memory, blkio, devices, freezer · 2013 г. — Docker использует cgroups + namespaces для изоляции контейнеров. Начинается контейнерная революция · 2014–2016 гг. — Разработка cgroups v2: унифицированная иерархия, лучшее управление · 2020+ гг. — cgroups v2 становится стандартом в дистрибутивах. Kubernetes, Docker переходят на v2
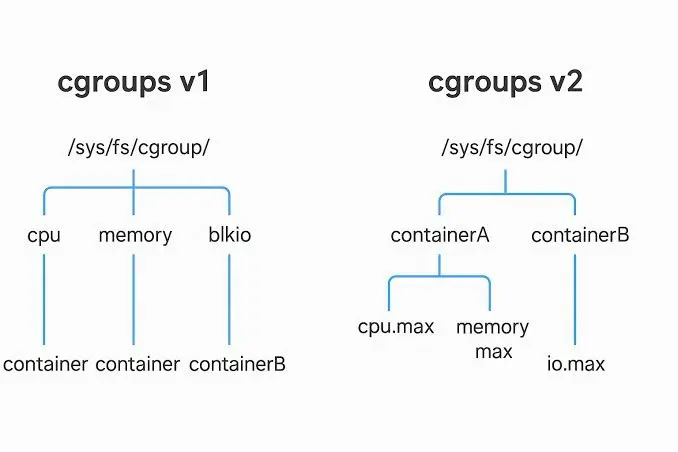
▫️Как устроены cgroups Иерархия групп — группы выстраиваются в дерево. Дочерние наследуют ограничения родителей, но могут их ужесточать. Подсистемы (контроллеры) — каждая отвечает за свой ресурс: · cpu — ограничение процессорного времени · memory — лимит оперативной памяти · blkio — ограничение ввода-вывода на диске · pids — максимальное количество процессов · devices — доступ к устройствам Интерфейс — всё управление через виртуальную ФС /sys/fs/cgroup/. Создаёте папку — появляется группа. Пишете лимиты в файлы — ограничения вступают в силу.
▫️Пример из жизни Ограничить процесс bash до 512 МБ памяти: mkdir /sys/fs/cgroup/memory/mygroup echo 536870912 > /sys/fs/cgroup/memory/mygroup/memory.limit_in_bytes echo $$ > /sys/fs/cgroup/memory/mygroup/cgroup.procs Теперь оболочка и все дочерние процессы не смогут использовать больше 512 МБ.
▫️Зачем это нужно · Изоляция контейнеров — Docker создаёт для каждого контейнера отдельную cgroup · Балансировка — в Kubernetes kubelet распределяет поды по cgroups · Мониторинг — точный учёт потребления ресурсов · Защита от DoS — программа с утечкой памяти не обрушит всю систему
▫️Культурный феномен · «Бэкенд контейнерной революции» — cgroups остаются в тени, но без них Docker был бы просто chroot · Systemd unified hierarchy — systemd взял управление cgroups v2, сделав их основой для сервисов · Спор — одни считают cgroups спасением от «соседей-обжор», другие — усложнением, убивающим производительность · Мем — «cgroups не виноваты»: стандартная фраза, когда контейнер всё равно съел память (обычно проблема внутри приложения)
▫️Современное положение (2026) · cgroups v2 — стандарт во всех основных дистрибутивах. Включены в ядре по умолчанию · Kubernetes — с версии 1.25 полностью поддерживает v2 и рекомендует их · Docker / Podman — используют v2 на современных системах · systemd — интегрирован с v2, каждая служба получает свою группу ресурсов · Новые контроллеры — в ядро добавляются подсистемы для управления cache и улучшенного учёта памяти · Будущее — cgroups останутся фундаментом. Следующий шаг — интеграция с eBPF для тонкого мониторинга
#cgroups #linux #контейнеризация #docker #kubernetes #devops #управлениересурсами