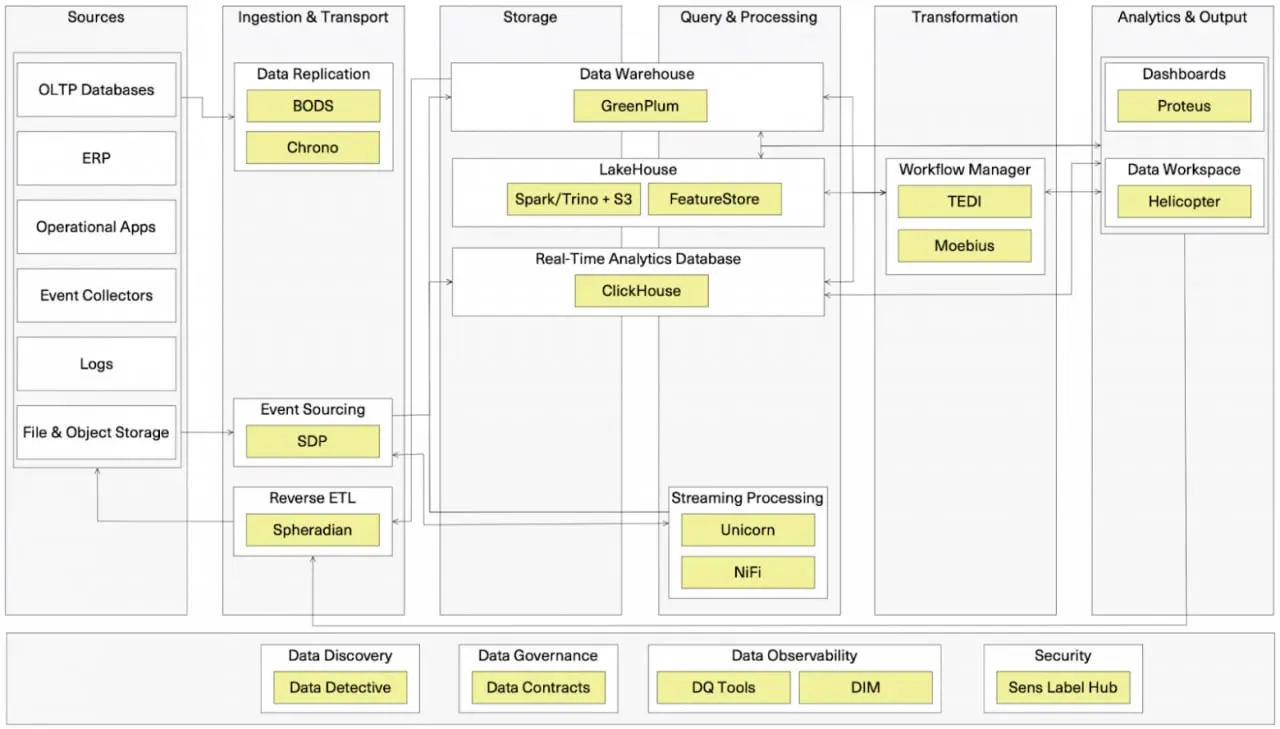
Дата-платформа Т-банка существует уже более 18 лет, и за это время прошла несколько поколений. В основе первого поколения лежал SAS. Да-да, у нас был SAS, но это было очень давно, и об этом уже почти никто не помнит (улыбка) Когда его перестало хватать, появился Greenplum. Когда и его перестало хватать ... мы поставили ещё один. И ещё, и ещё. Текущее поколение платформы состоит уже из 15+ кластеров и целой экосистемы сервисов, которые позволяют работать с ней большому количеству пользователей. Цифры говорят сами за себя:
*MAU: 25 тысяч пользователей; *Объем данных: 12 петабайт; *Ежемесячное количество запросов к данным: около 750 млн.; *Самый большой источник данных - 500 терабайт Всё возможно, но как работать с такими большими данными в Greenplum? Наш ответ - работать с ними уже в следующем поколении платформы данных, на которое мы сейчас активно переезжаем. Оно строится на архитектуре DataLakehouse. Ключевые технологии - S3, Spark, Trino. Как мы это делаем, как выглядят устроены новые компоненты и сам переезд, как мы выдерживаем такую нагрузку и объем данных - читайте в постах с хэштегом #overview