Как работают бандиты. От подхода к алгоритму
Серия постов про адаптивные эксперименты. Часть 2, алгоритмы
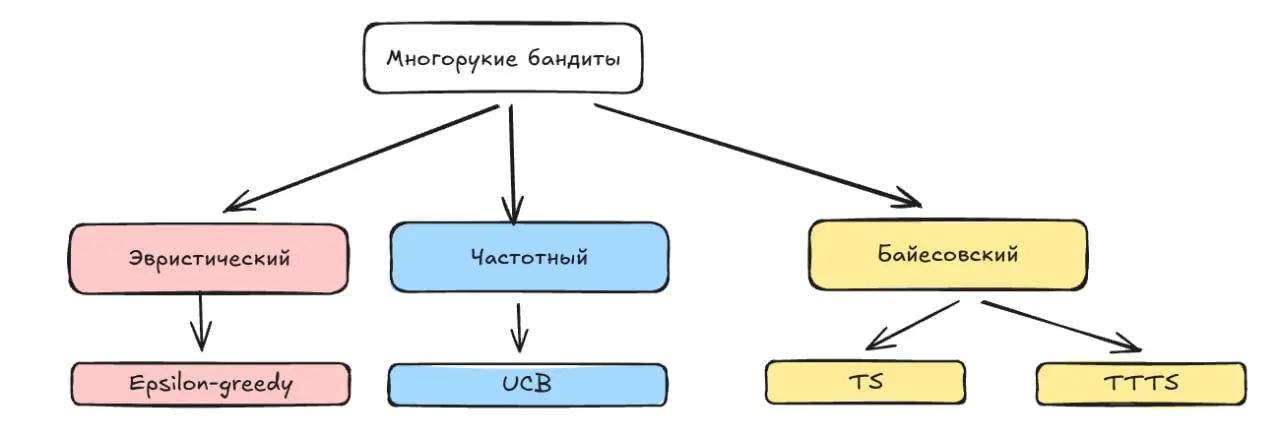
В прошлом посте разобрали, зачем нужны бандиты, а именно адаптивно перераспределять трафик между вариантами вместо того, чтобы неделями лить его поровну. Алгоритмы при этом по-разному балансируют между снижением потерь по дороге, то есть (regret) и скоростью нахождения лучшего варианта. Но как именно бандит решает, кому отдать трафик? Алгоритмов много, и для простоты их удобно разложить на три подхода в зависимости от их работы с неопределенностью:
🔢Эвристический подход Просто отдаем 90% трафика текущему лидеру, 10% с барского плеча раскидываем на остальных. Это epsilon-greedy, самый известный представитель этого класса и он же самый простой. Проблема базового epsilon-greedy в том, что он не учитывает неопределённость оценки: разница 5.1% и 4.9% для него одинаково значима вне зависимости от объёма данных. В реальности чаще используют decaying epsilon-greedy, где доля exploration-трафика (тех самых 10%) уменьшается по мере накопления данных, но это скорее костыль, чем принципиальное решение проблемы.
🔢****Частотный подход У каждого варианта есть реальная конверсия, мы просто её не знаем. UCB (Upper Confidence Bound) для каждого варианта берёт текущую оценку конверсии и добавляет сверху бонус за неизученность: чем меньше данных, тем больше бонус. Трафик идёт варианту, у которого оценка + бонус максимальны Получается, что вариант с небольшим количеством данных может получить трафик, даже если его среднее пока невысокое — потому что при малом объёме данных бонус большой и в сумме перевешивает. По мере накопления данных бонусы уменьшаются и алгоритм всё увереннее концентрирует трафик на реальном лидере
🔢****Байесовский подход Для каждого варианта строим апостериорное распределение (posterior) — это распределение вероятностей, которое показывает, какие значения конверсии мы считаем правдоподобными с учётом собранных данных. До начала эксперимента данных нет и распределение широкое, то есть правдоподобными выглядят очень разные значения конверсии. По мере поступления данных оно сужается и центрируется вокруг реального значения — мы всё лучше понимаем, какая конверсия у этого варианта на самом деле
Два байесовских алгоритма 🔢Thompson Sampling (TS) работает так: на каждом шаге из апостериорного распределения (posterior) каждого варианта случайно вытаскиваем одно значение конверсии, и трафик получает тот вариант, чьё значение оказалось наибольшим. Когда posteriors широкие и данных мало, случайные значения имеют большой разброс, поэтому даже слабый вариант может случайно выдать большое число и получить трафик (exploration). По мере накопления данных распределения сужаются и концентрируются около реальной конверсии, благодаря чему лидер начинает стабильно выигрывать (exploitation). Этот переход от исследования к эксплуатации происходит абсолютно автоматически и не требует ручного вмешательства
🔢Top-Two Thompson Sampling (TTTS) - обычный TS минимизирует regret, то есть меньше показывает плохие варианты, но он не оптимален по скорости идентификации лучшего. TTTS лучше фокусируется на различии топ-кандидатов, он целенаправленно распределяет трафик между текущим лидером и его ближайшим конкурентом, чтобы быстрее разрешить неопределённость именно между ними, а не размазывать трафик по всем
Что выбрать?
Если вам нужно просто и быстро запуститься, а точность идентификации не критична — epsilon-greedy. Работает, не требует байесовской модели, подходит для пилота
Если важно не показывать пользователям плохие варианты (высокая цена ошибки, любовь к пользователям) — Thompson Sampling. Он минимизирует regret и балансирует exploration и exploitation. Самый популярный выбор в индустрии, вариации TS активно используют бигтехи
Если главная задача как можно быстрее найти лучший вариант из множества кандидатов и regret AB теста для вас приемлем — TTTS. Но у всех байесовских бандитов есть общая проблема, на практике данные приходят не поштучно, а батчами, и это ломает статистику. Об этом в следующей части!