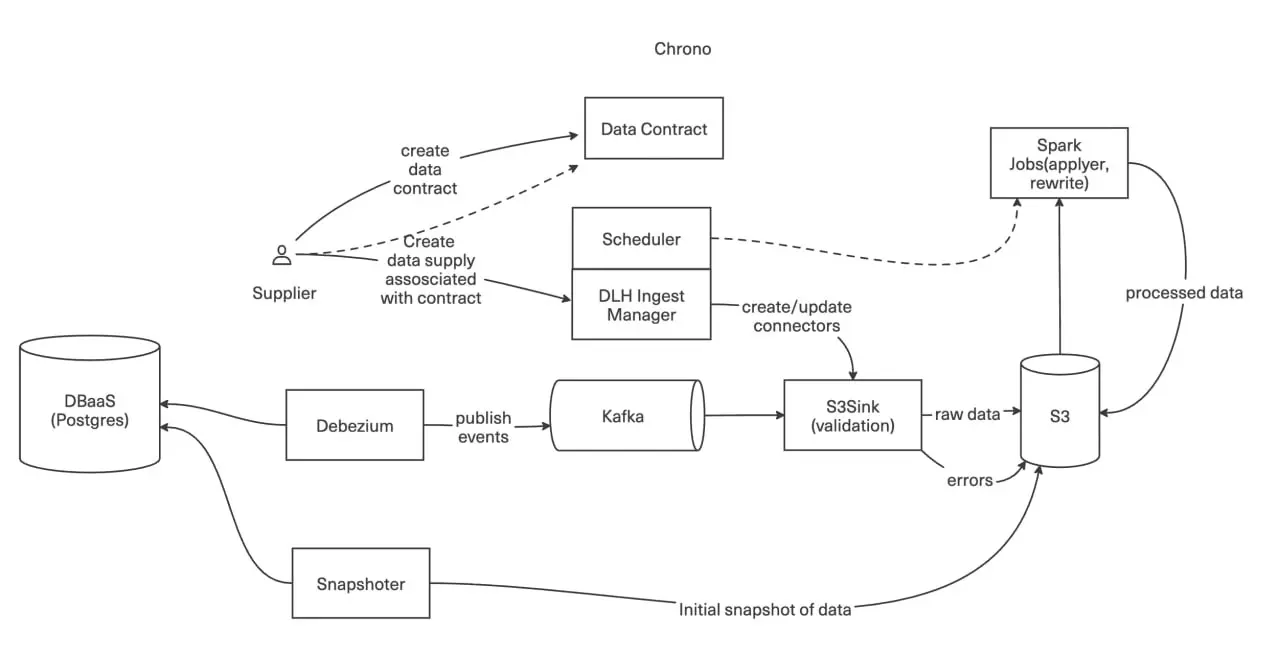
Иногда лезть в кодовую базу источника нельзя, некогда или просто незачем. Для таких случаев у нас есть Chrono.
Он использует подход CDC (Change Data Capture): вместо того чтобы просить источник что-то отправлять, мы сами считываем изменения прямо из РСУБД, в нашем случае большинство компонентов используют Postgres.
Под капотом — Debezium, который занимается захватом изменений. А первоначальный слепок таблиц делает наш собственный Snapshotter: он бьет данные на части и аккуратно дозирует нагрузку на базу-источник, чтобы не создавать лишних проблем в самый неподходящий момент.
Данные из Chrono попадают в Kafka, а дальше подхватываются тем же механизмом, что и в SDP — до самого S3.
Идеально для быстрого старта. Но есть нюанс — расскажем в следующем посте 👇