
🔧 Что под капотом у AI-агента? (мой опыт сборки)
Реализовал своего кодирующего агента по мотивам статьи.
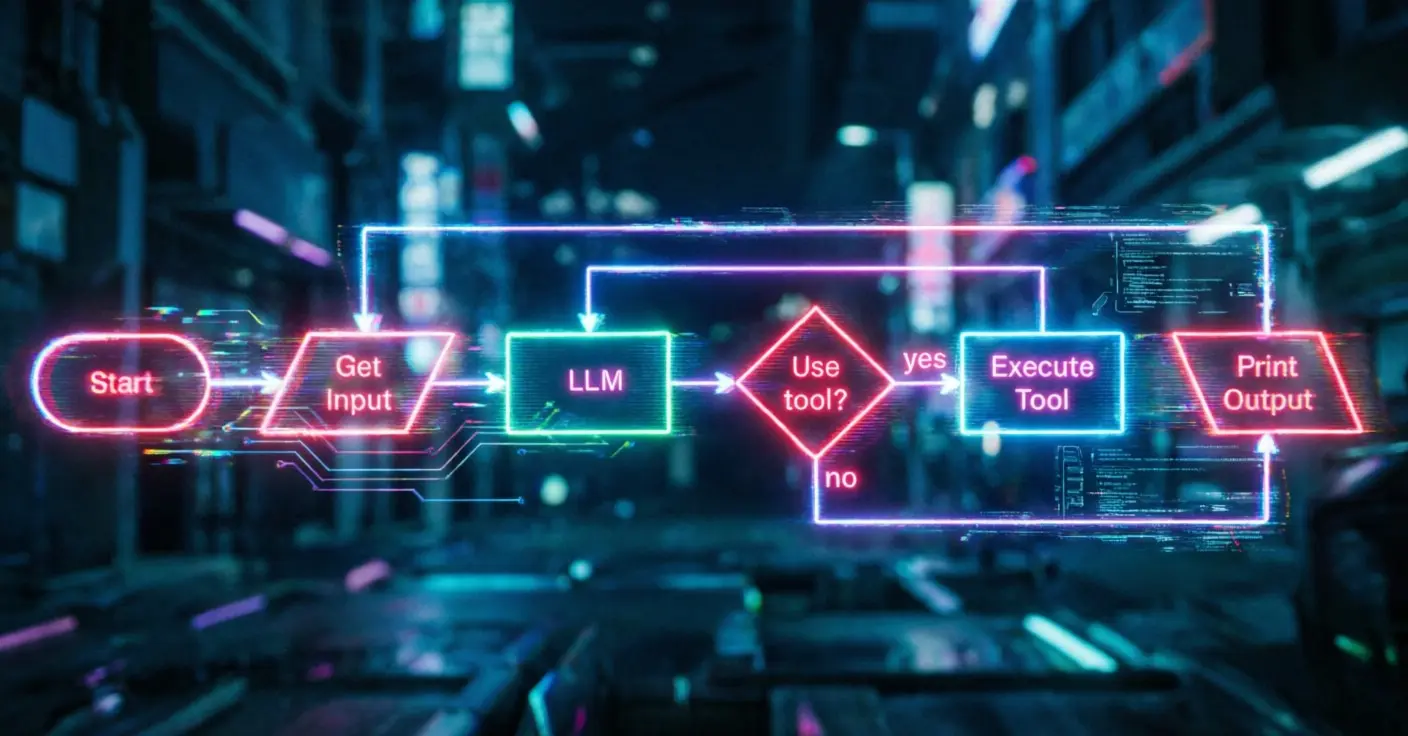
Агент ≠ LLM Агент = цикл { LLM + промпт + инструменты }
Модель решает, какой инструмент вызвать и с какими аргументами. Минимальный набор инструментов для кодирующего агента: - read_file - list_files - edit_file - text_search - опционально bash (но осторожно).
Пока не задумывался о реализации, казалось, что агенты — это специально обученные модели. Думал, будет сложно обучить модель. Как выяснилось, создание агента это совсем не про обучение.
Даже локальная модель на CPU может выполнять простые задачи написания кода и рефакторинга. Чем умнее модель — тем точнее. Простая будет чаще просить подтверждений, и придется потратить время на борьбу с галлюцинациями при отладке промпта, но тоже работает.
Для агента важно найти баланс между качеством модели и строгостью правил в промпте.
Главный инсайт из статьи ghuntley.com/agent: это знание помогает перейти от потребителя AI‑технологий к создателю полезных агентов. Потому что инструментарий можно расширять под любые задачи.
Теперь понятно, как устроены Cursor, Claude Code и т.п.
👉 Мой код: github.com/nikitasardov/cli-coding-agent 🔗 Вдохновляющая статья: ghuntley.com/agent
А вы пробовали собрать своего AI-агента? С какими подводными камнями столкнулись?


· вчера
Именно так. Несколько инсайтов из продакшена с Claude Code + MCP:
— Overflow контекста в длинных цепочках — главная ловушка. Решили через CLAUDE.md с явными ограничениями на задачу — Меньше инструментов = лучше решения. Убрали лишние MCP-серверы — качество сразу выросло — Детерминизм нулевой: один промпт → разные результаты. Критично для автоматизации
Твой вывод про баланс «качество модели vs строгость промпта» — абсолютно точно. Иногда простая модель + чёткий промпт выигрывает у мощной с размытым.
Ghuntley.com/agent кстати описывает архитектуру Claude Code изнутри — рекомендую.
ответить
коммент удалён