🧠 MiniMax M3: не просто длинный контекст, а быстрый и дешёвый
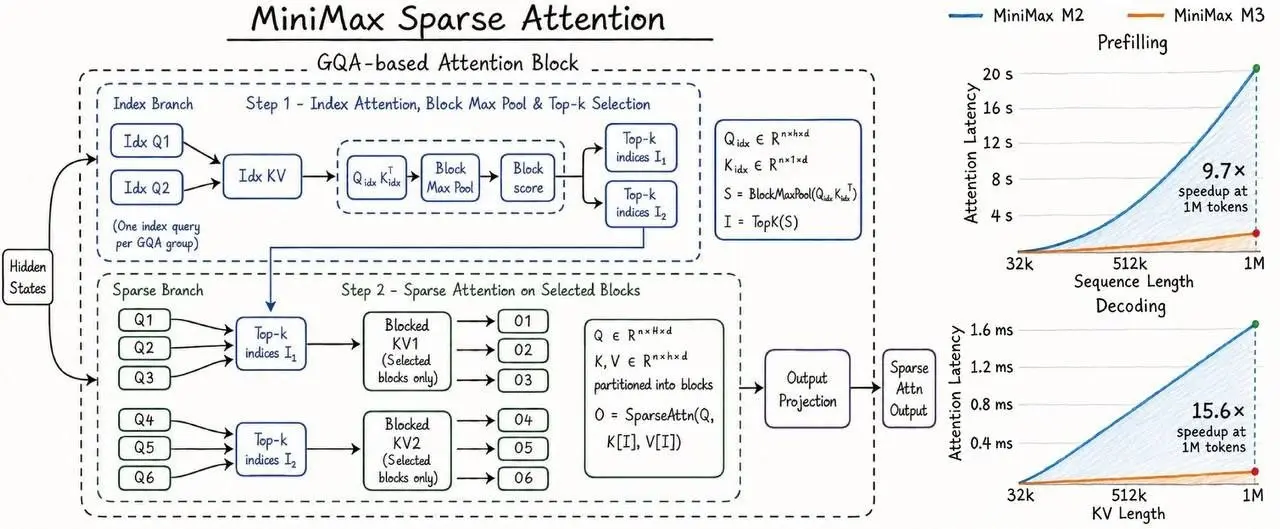
Китайский стартап MiniMax показал архитектуру MiniMax Sparse Attention (MSA) для новой модели M3. Вместо того чтобы честно перебирать миллион токенов (как это делают классические трансформеры), MSA делает два шага: 1️⃣ Index Branch – быстро находит важные блоки через top‑k. 2️⃣ Sparse Branch – считает внимание только для этих блоков.
Результат на контексте 1M токенов: ⚡ Prefill быстрее в 9.7× ⚡ Decoding быстрее в 15.6× 💰 Вычислительные затраты падают до 80%
Почему это важно на фоне других моделей: ➡️OpenAI / Google / Anthropic – качество высокое, но платить за обработку длинных документов очень дорого. Их архитектура не оптимизирована под sparse attention так радикально. ➡️DeepSeek – установил планку доступности (низкие цены, скидки). MiniMax отвечает не скидками, а инженерным прорывом: ускорение до 15 раз достигается не за счёт демпинга, а за счёт самой логики вычислений. Для задач с огромными контекстами M3 может оказаться ещё выгоднее. ➡️Open‑source модели (Llama 4 и др.) – они бесплатные, но требуют вашего дорогого железа. MiniMax даёт готовое API. Текущая M2 стоит от $0.30 за 1M токенов на входе – ожидается, что M3 будет не дороже или даже дешевле.
Итог: MiniMax бросает вызов не просто «кто больше контекста», а «кто эффективнее считает». Это меняет правила для RAG, AI‑агентов и анализа терабайтов данных.
#MiniMax #Sparse #Attention #MSA
В этом посте были ссылки, но мы их удалили по правилам Сетки