
Django/LLM, fallback при падении провайдера и подмене модели
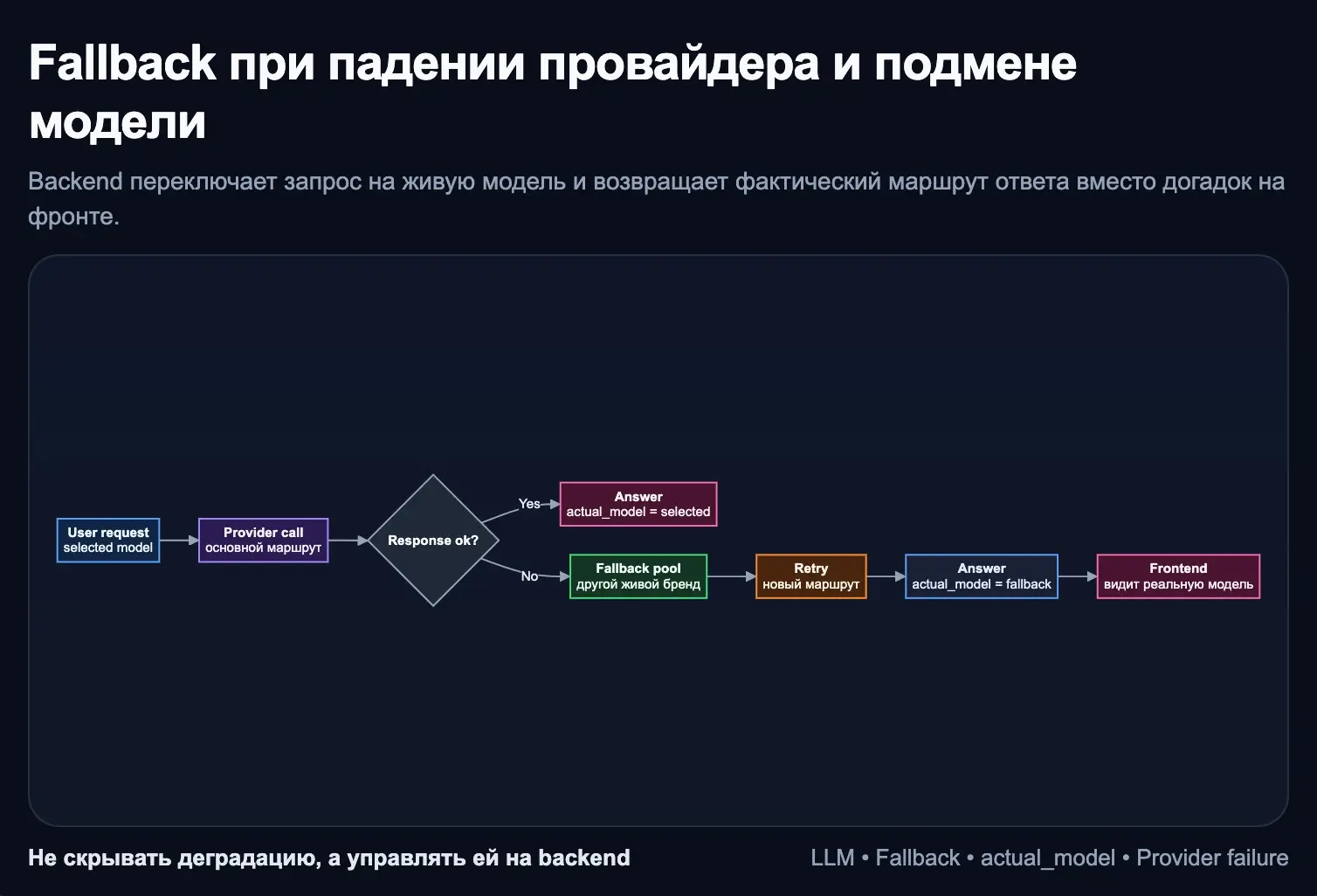
В LLM-интеграции одна из нужных проверок начинается в момент сбоя. Пока выбранная модель отвечает, система выглядит стабильной. Но как только провайдер возвращает ошибку, rate limit или временную недоступность, становится видно, есть ли у продукта архитектура деградации или только прямой вызов одной модели.
fallback должен жить на backend, а не на фронте. Если выбранная модель не отработала, система пробует другой живой вариант, желательно из другого бренда, и при этом возвращает не только текст ответа, но и фактическую модель, которая реально сработала. Без этого интерфейс начинает показывать одно, а backend уже живет на другом маршруте.
Тогда агрегатор перестает быть просто списком моделей и становится управляемым продуктовым контуром.
Статья на Хабр Витрина проекта: AI Chat github Проект: AI Chat Stepik: AI на Django и Next II
#django #python #typescript #llm #openrouter #ai #api #fullstack #webdevelopment #fallback


· 10.06
Делал похожее на Node.js. Помимо fallback добавил метрики по каждому провайдеру в Redis: P95 latency и error rate за последние 5 минут. Роутер выбирает не первую живую модель, а живую с лучшим текущим P95. Это ближе к circuit breaker чем просто fallback. Единственная проблема при нескольких инстансах надо синхронизировать эти метрики, иначе каждый инстанс принимает решение независимо и картина ломается.
ответить
коммент удалён
· 10.06
Метрики в Redis и выбор по P95 уже полноценный circuit breaker, а не простой fallback. Синхронизация между инстансами решается через Redis же, но тогда добавляется задержка на каждый запрос. Компромисс, обновлять метрики асинхронно, а для выбора использовать кэшированную статистику с небольшим TTL. Тогда инстансы не ходят в Redis на каждый запрос, но данные остаются согласованными в пределах, скажем, 5-10 секунд
ответить
ответ удалён