20 лет в реакторных цехах. Последний — в Jupyter Notebook
20 лет в реакторных цехах. Последний — в Jupyter Notebook 20 лет я занимался промышленным R&D и масштабированием химических производств — от лабораторной колбы до многотоннажного синтеза. Последние несколько лет перевожу этот опыт в инструменты Industrial AI: системы анализа технической документации, инженерные базы знаний и цифровые модели для поддержки разработки материалов.
Главный разрыв, который я вижу между производством и Data Science, прост. Data Scientist часто не знает, почему один и тот же датчик сегодня показывает корректные значения, а завтра — нет. Технолог зачастую не доверяет нейросетям, потому что не понимает границы их применимости. Мне интересно работать именно на этом стыке — там, где физика процесса становится ограничением для модели, а модель помогает инженеру быстрее проверить гипотезы.
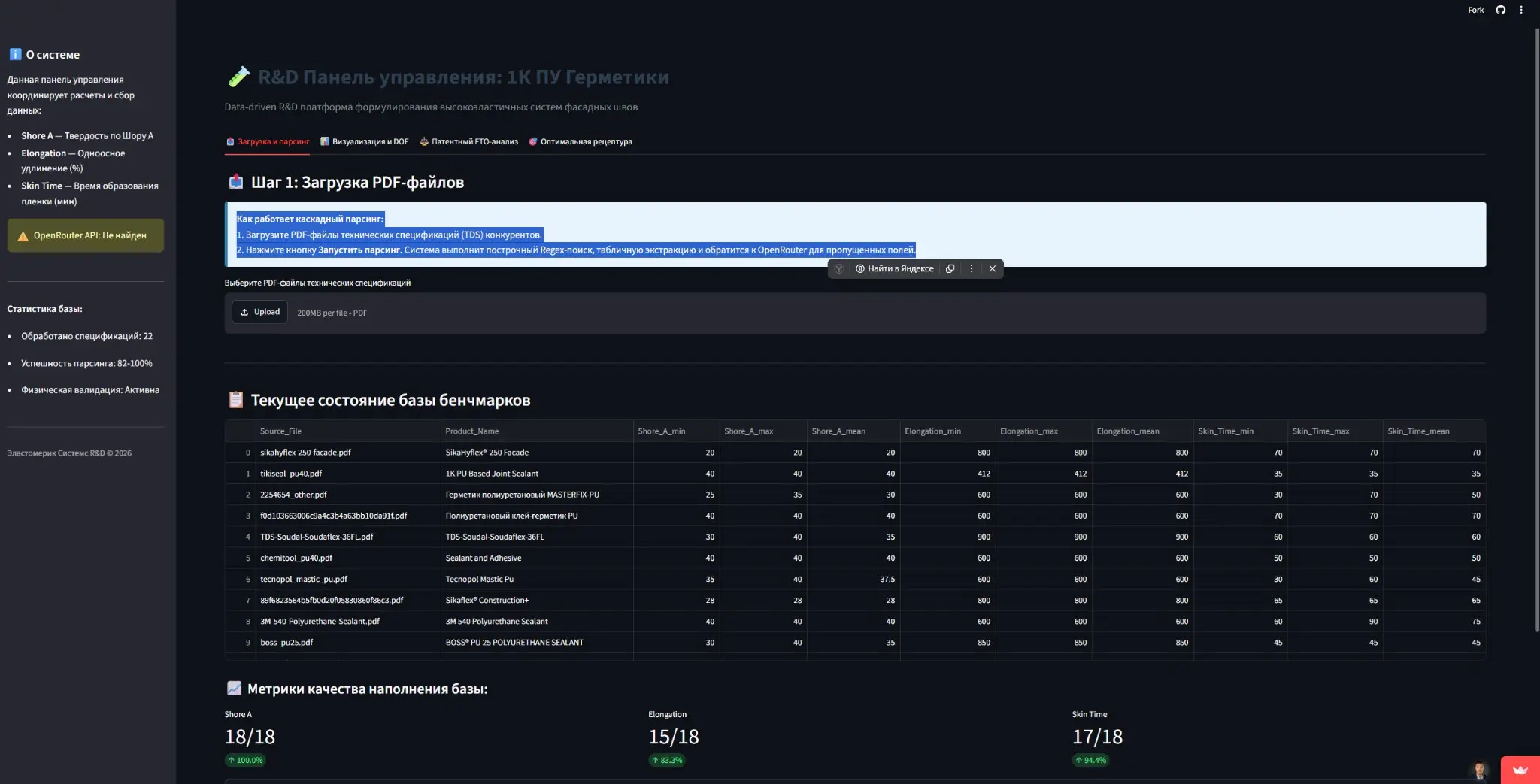
Недавно оформил в виде pet-проекта методологию разработки низкомодульного полиуретанового герметика.
Вместо классического подхода «один фактор за раз» построил цифровой R&D-конвейер:
• автоматическое структурирование TDS конкурентов; • предварительный анализ патентных ограничений; • статистическое планирование экспериментов (Box–Behnken); • поиск перспективных областей рецептурного пространства на суррогатной модели.
В результате матрица лабораторных экспериментов сократилась с 27 до 15 синтезов без потери информативности плана.
Важно: это in silico методология на синтетических данных. Реальный лабораторный синтез и валидация — следующий этап. Я сознательно не выдаю результаты моделирования за подтвержденную физику процесса.
🔹 Приложение: czeberyak-elastomeric-1k-pu.streamlit.app 🔹 Код: github.com/czeberyak/elastomeric_1k_pu
На этой странице хочу говорить о промышленном AI без хайпа — только о тех случаях, где модель действительно помогает инженеру принимать решения.