

Как мы сократили время OPTIMIZE в ClickHouse почти в 2 раза
Есть таблица на ReplacingMergeTree, для которой регулярно выполнялся:
OPTIMIZE TABLE schema.table FINAL SETTINGS optimize_throw_if_noop = 1;
Поначалу всё работало отлично. Но со временем таблица выросла примерно до 200 ГБ (в сжатом виде).
В какой-то момент начались инциденты.
📌Что произошло
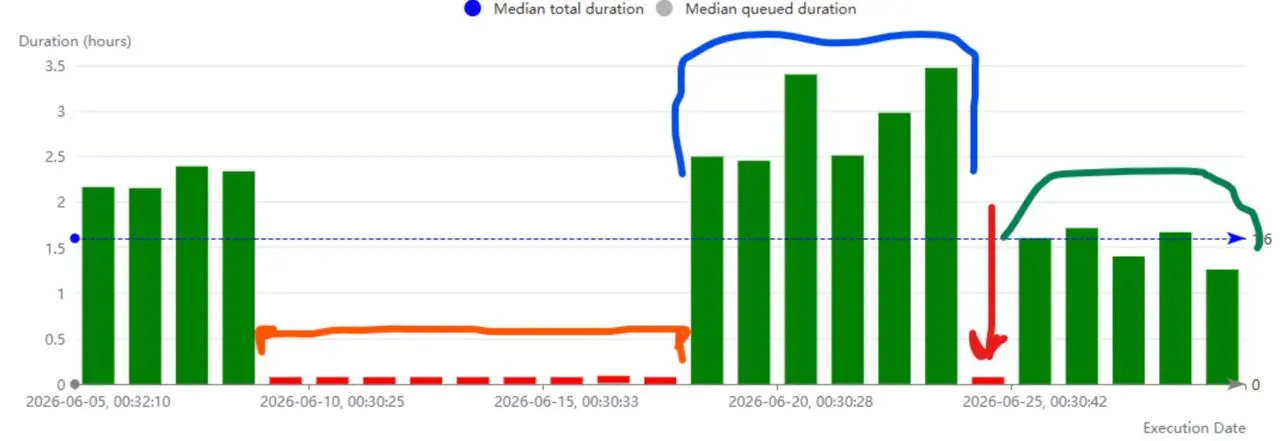
Таблица была непартиционированной, поэтому OPTIMIZE FINAL каждый раз фактически проходил по всей таблице. Когда объем данных вырос, оптимизация перестала укладываться в таймаут драйвера с ClickHouse. На графике это видно как серию падений DAG (оранжевая область).
Чтобы восстановить работу, пришлось просто увеличить timeout драйвера. Выполнение стабилизировалось, но появилась другая проблема – каждая оптимизация стала занимать 3–4 часа. По итогу Time to Market у нас пошел по одному месту.
📌Решение
Так как нужно было удалять дубли в рамках ключа, применили хеш-партиционирование по ключу сортировки разбив её на 16 частей:
PARTITION BY cityHash64(id) % 16
После этого:
- пересобрали таблицу;
- выполнили EXCHANGE TABLE;
- оптимизация стала выполняться параллельно по каждой партиции отдельно, а не по всей таблице сразу.
📌Итог
📊 На графике хорошо видно три этапа:
🟠 Инциденты – OPTIMIZE перестал укладываться в таймаут и начал падать. 🔵 Временное решение – Увеличили timeout соединения. Проблема исчезла, но время выполнения выросло до 3–4 часов. 🔴 Я тут как раз пересобирал таблицу 🟢 Окончательное решение – Перешли на хеш-партиционирование.
В результате время выполнения OPTIMIZE FINAL сократилось примерно в 1.5 раза, а сама операция стала значительно стабильнее.
Понятное дело, что мы можем еще поработать над параллельностью, над кодеками самих колонок, разложить не на 16 частей, а например на 32 и т.д. но важно понимать это инцидент, а не полноценная задача. Соответсвенно нужно сделать быстро и чтобы работало исправно, как только и тут зайдём на SLA в 2 часа, то начнём думать что делать дальше, вплоть до того чтобы оставлять только нужные данные, а остальные отправлять в архив.
**_____________________
Хочешь изучить Python и SQL записывайся на 1й поток "Буткемпик" через** @bootcampych_bot****, старт через 2 дня – 1 июля!
· 3 ч
Хороший способ, можно еще проверять только те партиции, которые были затронуты и оптимизировать только их
Если изменения происходят только за несколько последних месяцев, а табличка хранит годы истории, то это очень сильно помогает
Проверка какие партиции нужно оптимизировать select partition from system.parts where database='{database}' and table='{table}' and active=1 group by partition having count(*)>1 order by partition asc
Собираем optimize: for partition in partitions: if str(partition) in ('()','tuple()'): optimize_sql=f"optimize table {table_name} final settings optimize_throw_if_noop=1,distributed_ddl_task_timeout=3600" else: safe_partition=str(partition).replace("'", "''") optimize_sql=f"optimize table {table_name} partition '{safe_partition}' final settings optimize_throw_if_noop=1,distributed_ddl_task_timeout=3600"
P.S. Отступы для питона куда-то пропали, но надеюсь суть удалось передать
ответить
коммент удалён
· 3 ч
Спасибо большое. Думаю применим на практике
ответить
ответ удалён